Build a mass spectrometry analysis pipeline in Python using matchms — part II: Spec2Vec
After “part I” which gave an introduction on how to import, process, and analyze a tandem mass spectra dataset using Python and matchms, “part II” will add Spec2Vec to the game, a machine learning tool to assess spectrum similarities.
[last edit: 31/01/2023, using spec2vec 0.8.0 and matchms 0.18.0]
In part I of this tutorial, matchms, a Python library to import, process, and compare tandem mass spectrometry data was introduced. We imported a MS/MS dataset with spectra of natural products which we downloaded from GNPS. The data then was processed using matchms to gain more reliable metadata and remove possible noise peaks. This mainly included:
- metadata cleaning
- normalizing peak intensities
- removing small peaks (here simply: <0.01 of max peak intensity)
We will continue working with the data that we got after those processing steps and will then use it to compute spectrum similarities using Spec2Vec. So, to run the following code you would first have to run the processing from part I to continue here.
Let’s move to Spec2Vec now! Spec2Vec is an unsupervised machine learning technique that can learn relationships between peaks from co-occurrences across large(r) MS/MS datasets. It is mainly based on the Word2Vec algorithm which is well known in the field of natural language processing.

Spec2Vec can be used in two fundamentally different ways.
(1) Loading a Spec2Vec model which was pretrained on a large MS/MS dataset.
(2) A Spec2Vec model can be trained on the dataset of interest itself. This requires a sufficiently large datasets (at least several hundreds of spectra).
We will do both things in the following part of this tutorial.
Getting the required packages
If you have run part I before then you can simply add spec2vec by pip install spec2vec. Otherwise you can create a new environment by running the following:
conda create --name spec2vec python=3.8
conda activate spec2vec
conda install --channel bioconda --channel conda-forge matchms spec2vecImport the processed data from part I
If you did the data importing and processing as shown in part I then you can simply continue from there, e.g. by importing the data that was stored after the processing:
import os
import numpy as np
from matchms.importing import load_from_jsonpath_data = os.path.join(os.path.dirname(os.getcwd()), "data") #"..." enter your pathname to the downloaded file
file_json = os.path.join(path_data, "GNPS-NIH-NATURALPRODUCTSLIBRARY_processed.json")
spectrums = list(load_from_json(file_json))
1. Load a pretrained Spec2Vec model
For many use-cases we would not advice to retrain a new model from scratch. Instead a more general model that has been trained on a large MS/MS dataset can simply be loaded and used to calculate similarities, even for spectra which were not part of the initial model training.
Here we can download a model trained on about 95,000 spectra from GNPS (positive ionmode) which can be downloaded from Zenodo.
Now let’s import this model.
import gensimpath_model = os.path.join(os.path.dirname(os.getcwd()),
"data", "trained_models")
# enter your path name when different
filename_model = "spec2vec_AllPositive_ratio05_filtered_201101_iter_15.model"
filename = os.path.join(path_model, filename_model)model = gensim.models.Word2Vec.load(filename)
It is very important to make sure that the “documents” are created the same way as for the model training. This mostly comes down here to the number of decimals which needs to be the same here than for the pretrained model. To inspect the words the model has learned, we can look at model.wv which is the "vocabulary" the model has learned. Let’s for instance see how a word looks like:
model.wv.index_to_key[0]This should give peak@289.29, which also tells us that the model was trained on words with 2 decimals (for Spec2Vec < 0.5.0 you need to run next(iter(model.wv.vocab) instead).
Calculate spectrum similarities
Now comes the fun part. With both spectrums and a trained model we can start computing Spec2Vec spectrum similarities. First, we will initialize Spec2Vec by running:
from spec2vec import Spec2Vecspec2vec_similarity = Spec2Vec(model=model,
intensity_weighting_power=0.5,
allowed_missing_percentage=5.0)
Apart from using the before loaded modelwe here set two parameters. The model itself will convert spectrum peaks (here: “words”) into abstract vectors (“embeddings”) which are then added up to give us a spectrum embedding. The parameter intensity_weighting_powerdefines by what power of its intensity we scale each word vector, usually we use 0.5. The allowed_missing_percentagespecifies what percentage of a spectrum is allowed to be unknown to the used model.
Let’s now compute some actual Spec2Vec spectrum similarities, for instance between for all possible pairs within our list of spectrums by running:
from matchms import calculate_scoresscores = calculate_scores(spectrums, spectrums, spec2vec_similarity,
is_symmetric=True)
In the example given here we set is_symmetric=True to indicate that both inputs are the same (the calculation can then be a bit faster because score[i,j] = score[j,i]). In general, if you want to get Spec2Vec similarities between two different list of spectrums, you would have to run:
scores = calculate_scores(spectrums1, spectrums2,
spec2vec_similarity)You might notice a printed warning saying “Found 1 word(s) missing in the model. Weighted missing percentage not covered by the given model is 0.19%.”. Don’t worry. This simply means that 1 word (=1 peak) that occurs in our spectrums was not part of the loaded model. Depending on how important that peak is (its intensity) this could be a problem. However, here it only corresponds to a missing percentage for that particular spectrum of 0.19% which is far below the above set threshold of allowed_missing_percentage=5.0. If it would have been above the set threshold the run will fail in which case you either have to remove the respective spectra, retrain the model, or set the threshold to a higher value.
And the following will give you the best Spec2Vec scores for a particular spectrum (here as an example I used spectrums[11]).
best_matches = scores.scores_by_query(spectrums[11], sort=True)[:10]
[x[1] for x in best_matches]More interesting for most researchers might be SMILES of the best scoring spectra, which can be accessed in a similar way.
[x[0].get("smiles") for x in best_matches]The respective compounds can also be plotted, which we will also do later in the 2nd part of this section (with a new model trained from scratch).
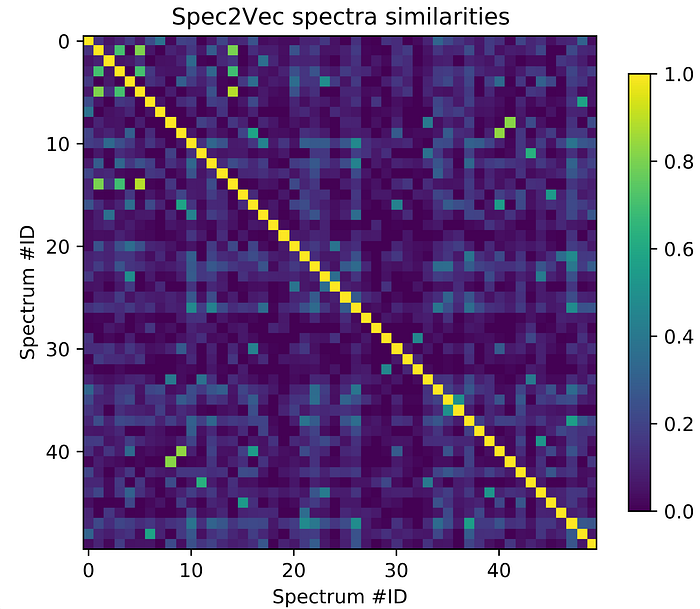
Instead of looking at a few individual query spectra, lets have a look at the “bigger picture” by plotting part of the similarity score matrix we just computed to generate Figure 2.
from matplotlib import pyplot as pltscores_array = scores.scores.to_array() # for matchms >= 0.18.0plt.figure(figsize=(6,6), dpi=150)
plt.imshow(scores_array[:50, :50], cmap="viridis")
plt.colorbar(shrink=0.7)
plt.title("Spec2Vec spectra similarities")
plt.xlabel("Spectrum #ID")
plt.ylabel("Spectrum #ID")
plt.clim(0, 1) # Spec2Vec scores can be between -1 and 1
#plt.savefig("spec2vec_scores.png")
2. Train a new Spec2Vec model from scratch
Training a Spec2Vec model is fairly straightforward and relatively fast (usually minutes to one hour max). In general, training a new model from scratch makes sense when a lot a data is present to train on as it gives more options to optimize the results when compared to simply using a pretrained model as done above.
First, the spectrum data has to be converted into “documents” where peaks and neutral losses have become “words” (e.g. peak@289.29). This can be done by running:
from spec2vec import SpectrumDocumentspectrum_documents = [SpectrumDocument(s, n_decimals=2) for s in spectrums]
Then, a new model can simply be trained by using train_new_word2vec_model. The following code will create a new model which is trained for 25 iterations (for machine learning people: that is ”epochs”) on 2 workers (you can change this, e.g. to 4 if you have 4 cores, the difference is not drastic though). Depending on your hardware, the training of this model should not take longer than a couple of minutes.
from spec2vec.model_building import train_new_word2vec_modelmodel_file = "tutorial_model.model"
model = train_new_word2vec_model(spectrum_documents, iterations=[25], filename=model_file,
workers=2, progress_logger=True)
The above code snippet will automatically save the model under the name tutorial_model.model, which could later load again by running model = gensim.models.Word2Vec.load("tutorial_model.model").
Calculate spectrum similarities
Once we have our trained model we can again (as above with the pretrained model) compute spectrum similarities.
from matchms import calculate_scores
from spec2vec import Spec2Vecspec2vec_similarity = Spec2Vec(model=model, intensity_weighting_power=0.5,
allowed_missing_percentage=5.0)scores = calculate_scores(spectrum_documents, spectrum_documents, spec2vec_similarity, is_symmetric=True)
Here again we can search for the best matching compounds according to Spec2Vec.
best_matches = scores.scores_by_query(spectrum_documents[11], sort=True)[:10]
[x[0].get("smiles") for x in best_matches]And we can plot the resulting smiles to .png files by running:
from rdkit import Chem
from rdkit.Chem import Drawfor i, smiles in enumerate([x[0].get("smiles") for x in best_matches]):
m = Chem.MolFromSmiles(smiles)
Draw.MolToFile(m, f"compound_{i}.png")
The best 8 matches are plotted in Figure 3.
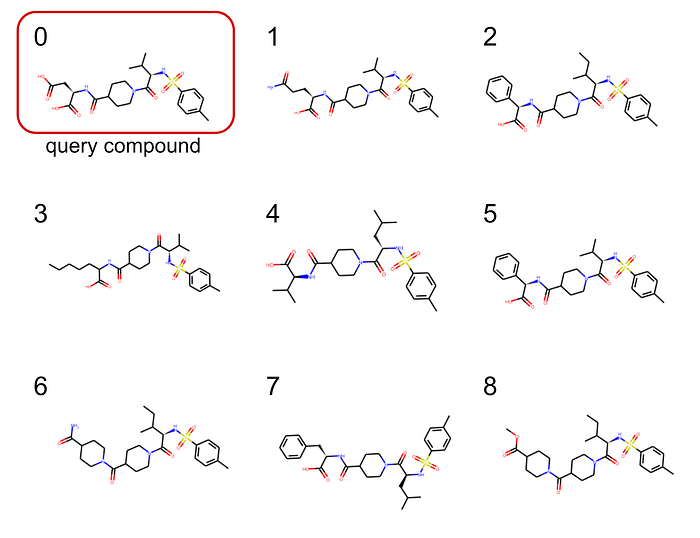
This example in figure 3 looks already quiet promising and all selected candidates clearly show chemical similarities! But this is of course just one mostly random pick out of many spectra. In our Spec2Vec paper we compared the different similarity scores (Cosine, modified Cosine, Spec2Vec) in much more detail and found that Spec2Vec often — but not always — outperformed the classical scores. We also found a general trend that such scores are generally more reliable for larger compounds, supposedly because those will come with a higher number of chemically meaningful fragments.
OK. Done for now. Really curious to see what you can get out of Spec2Vec!
Other parts of this tutorial
part I — Build you own mass spectrometry pipeline
part II — Compute spectra similarities using Spec2Vec
part III — Network analysis based on spectra similarities
matchms library
matchms is freely available and open-source. You can find the code on Github, the package is available as conda package (recommended) or from pypi. It was developed by a bunch of very nice people (see here) and is published in Joss.
spec2vec library
Spec2Vec is of course also freely available and open-source. You can find the code on Github, the package is available as conda package (recommended) or from pypi. The article published in PLOS Computational Biology can be found here.
You can find more information in the matchms documentation and the spec2vec documentation.
Code
The code shown in this blog post can also be found as Jupyter notebook on GitHub.
Help us develop matchms and spec2vec further!
We really hope that matchms will help people to build new, better analysis pipelines and that spec2vec can improve your analysis results. So, please help us to further improve matchms and spec2vec. You can help us by (1) Cite our work if you use our package for your research: matchms article in JOSS, spec2vec article in PLOS Computational Biology.
(2) Let us know if you run into any issues using matchms and/or spec2vec, or if you are missing any key functionalities! You can simply do so by starting a new issue on the matchms GitHub repository, or contact me on twitter @me_datapoint.
You are of course more than welcome to also become an active contributor to the package and help extend its functionality!
(3) Please let us know if you successfully applied matchms and/or spec2vec in your research project (makes us happy + we can maybe share the good news!).
Thanks a lot!
I would like to thank Carlos Martinez-Ortiz, Justin van der Hooft and Kontoueftychia for helpful comments and suggestions on this blog post.

