The Utopic Git History
If you love this article and can’t wait to read more about The Utopic Git History, please see this follow-up article by Abel.
A quick way to create discord among a group of developers is to discuss Git. More specifically, whether to merge, rebase, or squash. There are many arguments around this, simply because it involves opinions on whether the end result is good or bad. Some of these arguments verge from bad experiences with extreme cases. The most common case that I encounter is the dreadful huge pull request.

A very large pull request is one containing changes in many files, possibly with many commits. Even if best practices are followed — which we will discuss here — it is a big endeavor to review such a pull request. If best practices are not followed, then it is a nightmare, and the end result is ugly. Some common issues with the result are:
- Sequential commits that seem unrelated.
- Many commits “fixing” the same thing.
- One huge (probably squashed) commit.
Let’s discuss how to avoid this issue, and touch on the merge vs rebase vs squash debate on the way there.
Target audience: This post should be useful for anyone interested in best practices with Git, or intermediate/advanced usage of Git. It also contains opinions on Git rebase and squash, so it might trigger some people.
UGH — Utopic Git History
Note: UGH should be pronounced with disdain and eye-rolling.
The main idea behind what I will call UGH workflow is atomic git commits. This is not a new subject, you can find a few blog posts about it — in fact, I just found out about the Git Legit talk by Pauline Vos and I strongly recommend watching it.
If you haven’t heard of atomic git commits, let me give you a short introduction. The basic idea of an atomic git commit is that it contains the shortest amount of work that does what it is supposed to do. That is, less work would not be enough to do the task, and more work would be going out of scope.
Pauline describes three features of an atomic git commit, the first is what I just described. I normally like to think of the other two separately because they are good practices that we should follow even if we don’t do atomic git commits: (i) make sure that new commits do not break the code and (ii) have a clear and concise commit message. However, I understand the need to explicitly mention them, so that’s why I just explicitly mentioned them as well.
If every commit is an atomic commit, then we have a beautiful git history. Every commit passes tests, so we can easily navigate around. Every commit has a non-creeping purpose, so we can cherry-pick them more easily. Every commit is self-contained, so we can revert them trivially. It is almost utopic, but it is actually attainable.
If a pull request made of atomic git commits passes our way, we can review each commit individually, making our life easier. Then, what is the end result of our three merging strategies (as given by GitHub)?
Merge commit
A merge commit will be a new commit with a message like “Merging PR #123 from branch featureX”.
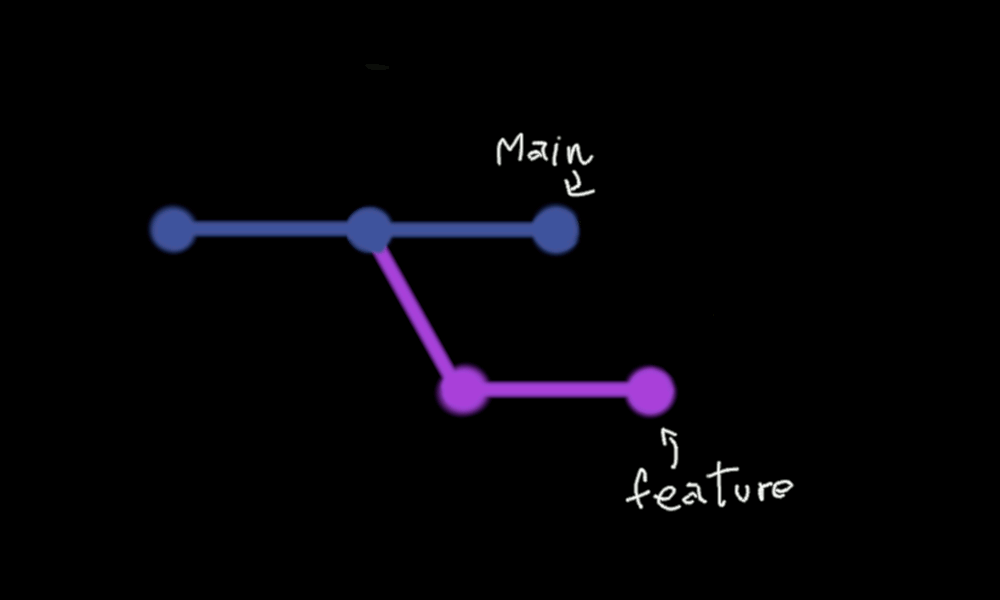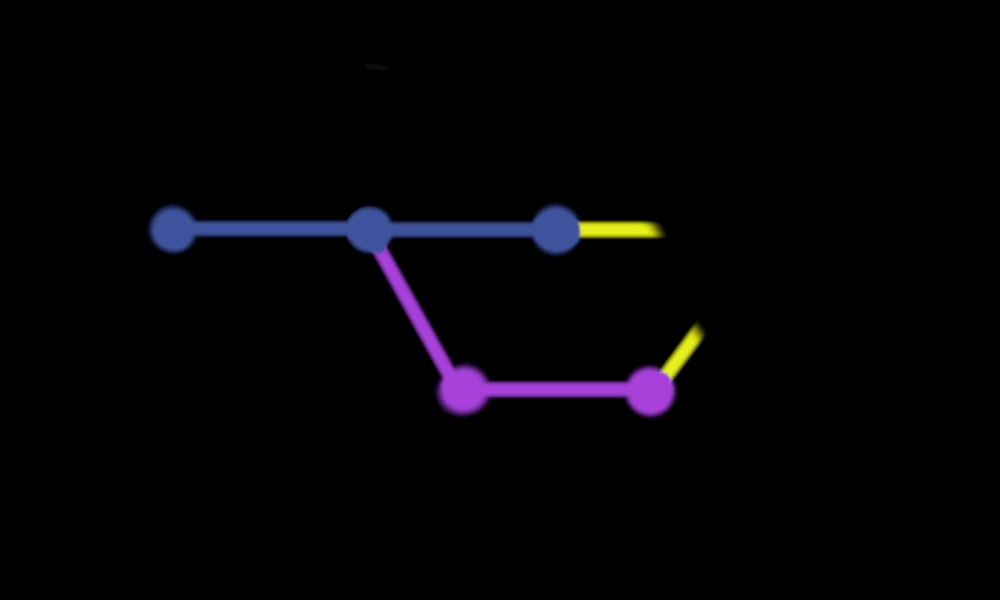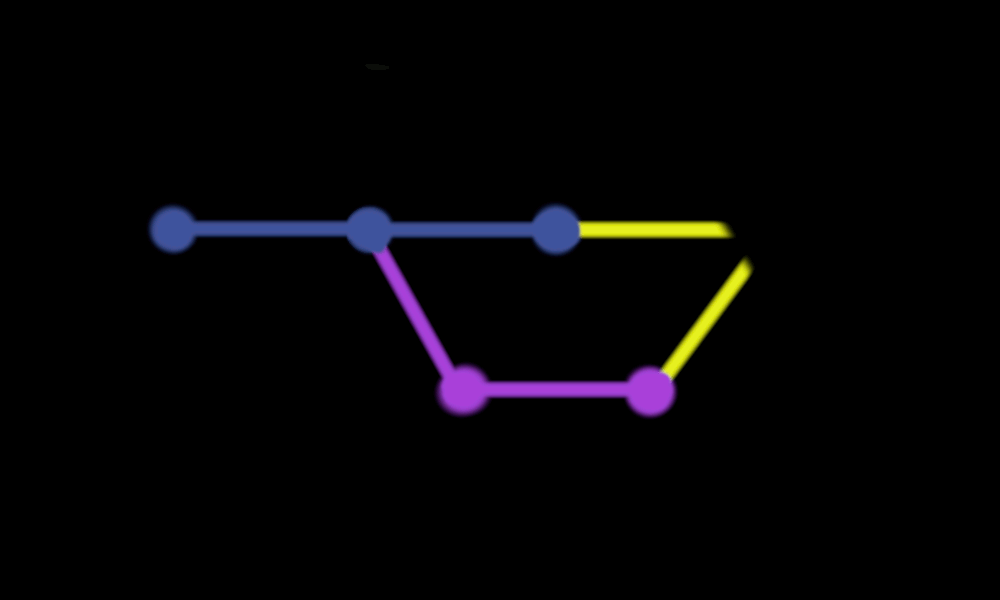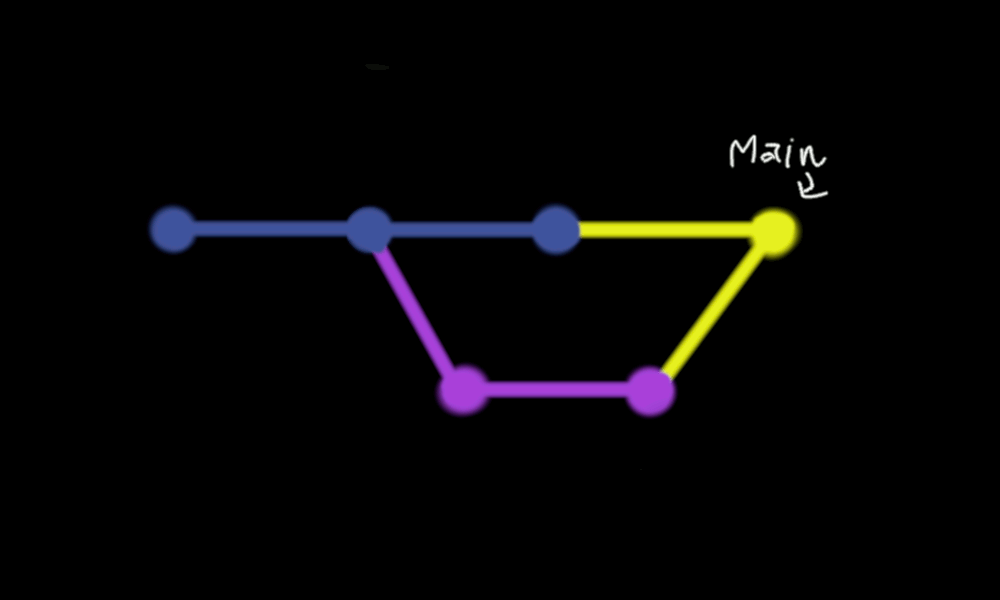
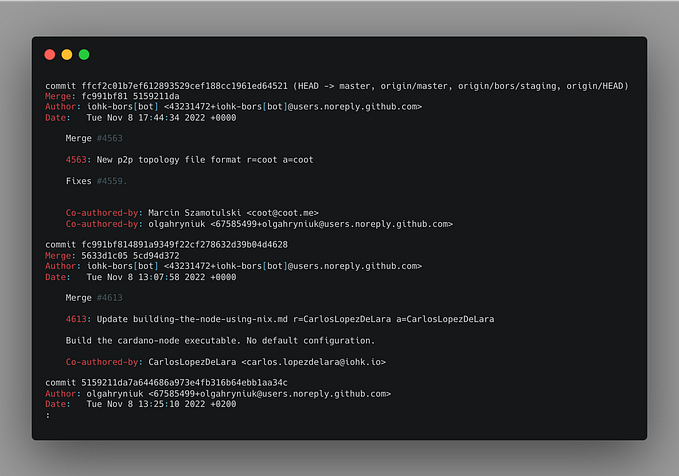
Here is an example from a real GitHub repository:

Personally, I don’t think that this extra commit is very useful. Even when all commits in the branch are pristine, passing, and having a great message, we still have this “parallel” development, which does not add any useful information. Furthermore, the merge commits themselves are not atomic.
Squash
Squashing is simply creating a single commit with the content of all commits, and rebasing the result.

The default commit message will change the title of the commit to something like “Title of the pull request (#pr)”, and then the old commit messages will be aggregated into a single commit message. This is a problem because now we have taken all atomic git commits and thrown their atomicity away.
The squash frequently comes into play when the pull request does not contain atomic git commits. Then it might be better to squash and have a single commit than a larger mess. If the resulting commit is atomic, then that is great. Otherwise, we have scope creep.
Rebase and don’t squash
Rebasing without squashing means rebasing the current branch on top of the current main and merging with fast-forward, i.e., not creating any new commit and simply updating main's pointer.

Here is an example from the same GitHub repository, from a later date:

The end result contains only main. There is no information that there ever was a feature branch.
This strategy was shown for last because it is my preference, but also because it is the only one of the three that will consistently keep the commits atomic — assuming that we have achieved a pull request with atomic commits.
How to achieve atomic git commits
Here are some tips to make pull requests with atomic git commits:
- If there are too many commits, use
git rebase -ito reorder, fix, squash or edit commits. - If there is uncommitted work that touches more than one topic, use
git add -pto add the parts that make sense for a single commit. - If there are commits from different scopes,
rebaseinto new branches. - Use
git commit --amendto fix the current commit. - Use
git push --forceto update the branch online (themainbranch can be protected somainis not accidentally rewritten). - Use a pre-commit hook to avoid having to create extra “fix linter” commits.
- Be prescient and write perfect commits — but you knew that already ;)
Once again I recommend Pauline’s Git Legit talk for more detailed examples but feel free to leave a comment here if you think of a situation that needs more care.
More utopia, please
The second part of the UGH workflow is to do the same for branches, and therefore, pull requests. In other words, the pull request must have the least amount of commits necessary to do what it is supposed to do. You can read a blog post about this by Fagner Brack.
If each commit tells a story, and they are in an order that makes sense, reviewing the pull request is much easier. Even if the pull request is still huge, it can be reviewed one commit at a time.
When reviewing, or receiving reviews, we should be vigilant of scope creep. The PR should do only what it is supposed to do.
But what is the PR supposed to do?
This is the harder part because it is not just git anymore. There are different approaches to determining what is a PR, but the one I have the most experience with is to relate them with issues. In other words, the issue defines the topic, or scope, of the PR. Following this approach, an atomic definition would be:
- Each pull request should close one, and only one issue.
- Each issue should be small enough to not creep into more than one topic.
Clarification: not every issue leads to a pull request, but every pull request requires an issue.
To achieve this, one has to
- Break issues into smaller issues.
- Create new issues for every desired change.
- Merge incomplete issues and close duplicates.
The actual size of the issue depends on how the team works, and who creates the issues. Some issues are user stories that involve many tasks. Some are bug reports. Some are tech-debt opportunities. Some are users’ questions.
Issues that involve many tasks are sometimes called epics. One way of dealing with epic issues is to create separate issues for each task — see the next section — but you could just as well have a larger pull request with one commit for each task. There is no one-size-fits-all solution.
I find that it helps a lot to work on an epic issue as a whole, then split it into smaller parts a posteriori. Then I make separate branches and create pull requests one at a time. One shortcoming of this approach is that if the reviewer makes big suggestions to one pull request, the other branches might be heavily affected.
Extreme UGH
What if we take these atomic definitions to the extreme?
One commit per pull request.
Since the issue is minimal, then it should be fixable with a single commit, right? Otherwise, the issue would not be minimal.
Why is this extreme?
- The reviewer and the developer must share the context. For instance, there might be dependencies between pull requests by the same developer. If the reviewer does not have that clear, then the pull request can actually be harder to understand than a single larger PR.
- It can be hard to know beforehand how to break an epic issue. Sometimes we only know how to break an issue after working on it. But what if we are not the ones responsible for updating the issue? Then we need to create a demand for the issue to be broken and wait until work can be restarted.
- Sometimes the code base is not modular enough. We might need API changes for a different part of the code. Scope creep might be unavoidable due to technical debt. If there is time, though, trying to pay this debt as a separate issue might be better.
Be aware of these limitations. Trying to achieve UGH can lead to loss of friends, or worst, productivity (this is a joke, managers).
Self-inflicted UGH
A good way of starting using UGH is to follow the workflow on your own, before trying to enforce it on the team.
- Make sure that your pull requests are atomic, even if nobody is enforcing UGH.
- As long as you’re the only one touching your branch, force-pushing won’t break anybody’s work.
- When you have to update your pull request because of conflicts with
main, you can rebase your branch instead.
This helps you practice and might help your team to see the benefits.
Finally, I chose the name Utopic Git History (UGH) to remind us of two things:
- It can be very obnoxious to insist on the workflow (hence the ugh sound), especially when reviewing pull requests.
- It is utopic in the sense of being unattainable in practice (for extended periods of time). Take parts of the idea and test them.
The best way to achieve UGH is to create a good culture first.
I actually don’t have any project that fully follows the UGH workflow, but I try to follow it with my personal commits, and I use rebase in many repositories. I spent a decent chunk of time helping people to update their workspace after their pull request was rebased (sometimes deleting everything and starting over was the chosen solution). It is not trivial to adopt this strategy for the whole project, but I can certainly say that it helped me learn more about Git.
Let us know if you (try to) use UGH or similar for your projects.
Many thanks to our proofreaders and reviewers, Sander van Rijn, Patrick Bos, Pablo Rodríguez-Sánchez, and Candace Makeda Moore.