(Nano)Publish your research with Python
Using nanopub, a high-level, user-friendly python interface to the nanopublication network

By Robin Richardson and Sven van der Burg
Those familiar with the world of academic research will be equally familiar with the old maxim, publish or perish. Indeed, communicating the results of scientific research is arguably the most important function of a scientist. For academics, this almost always means traditional publishing in journals — lengthy and information-rich research articles written in a natural language such as English, with all the accompanying ambiguities and misunderstandings.
There are millions of papers published every year, which is far too many for a human to read or reason about. There also exist many scientific results that, despite being potentially useful to other researchers, are not yet sufficiently developed to warrant an entire research article. How do we formally communicate such findings such that they may be cited and credit attributed accordingly? One means of achieving this is to use ‘nanopublications’.
We wanted to unlock the power of this way of creating and preserving knowledge to Python users. Today, we proudly present to you the result of this desire: the nanopub Python library.

What are nanopublications?
Nanopublications are a formalized and machine-readable way of communicating the smallest possible units of publishable information.
Here is an example nanopublication of an inter-species interaction observation between a bird and an insect (it can be found on the nanopub server here):

You need to speak some RDF in order to understand this, but if you squint a bit you can read that:
- The bird (Picoides villosus) ate a beetle (Ips). A
- This inter-species interaction took place in conifer woodland on the date of 1962–12–01. B&C
- This observation came from a 1985 paper by Otvos & Stark. D
- The information was extracted from the dietdatabase. E
The bold letters (A-E) correspond to the circles on the left side of the image above, indicating the location of these bits of information in the RDF.
Anatomy of a nanopublication
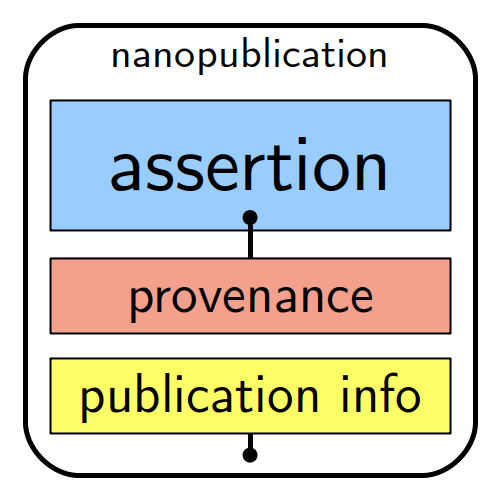
As can be seen in this image, a nanopublication has three basic elements:
- Assertion: The assertion is the main content of a nanopublication. This is generally some kind of scientific claim (an observation, result, interpretation of someone else’s result etc.)
- Provenance: This part describes how the assertion above came to be.
- Publication Info: This part contains metadata about the nanopublication as a whole, such as when and by whom it was created.
In what way are nanopublications machine-readable?
Nanopublications are made up of Linked Data: structured data which is interlinked with other data so it becomes more useful through semantic queries. In more concrete terms, you can think of this as a network of concepts like organisms, places and dates (nodes) and the relationship between them (edges). This formal structure allows computers to process it unambiguously in a way that natural languages such as English cannot be.
This allows for queries like:
- Which species of insects were observed to be on the menu of Picoides villosus (a type of bird)?
- Give me all nanopublications which describe historic events happening between 50 BC and 40 BC which mention Cleopatra VII.
Let’s now see what this might look like with our python library.
How do I do that with python?
The nanopub library provides a high-level, user-friendly python interface for searching, publishing and retracting nanopublications. The development repository can be found here with detailed documentation here. nanopub is available on the Python Package Index, so setup should be as simple as typing:
pip install nanopubIn your python script, you can then set up the nanopub client:
The client carries out all searching, fetching, publishing, retraction etc of nanopublications from the servers.
For example, if you want to e.g. search for all nanopublications containing the text Picoides:
which returns two results both pointing to the example nanopublication we just discussed:
{'np': 'http://purl.org/np/RAMzGwLotMRSQTHRCS15B6hvuYSyEupGnxZaFU3EmcItA', 'description': 'Inter-species interaction of Picoides villosus with Ips', 'date': '2020-12-24T10:51:43.931Z'}
{'np': 'http://purl.org/np/RAMzGwLotMRSQTHRCS15B6hvuYSyEupGnxZaFU3EmcItA', 'description': 'Picoides villosus', 'date': '2020-12-24T10:51:43.931Z'}You can then fetch a specific nanopublication directly using its URI:
This snippet will fetch the nanopublication we discussed earlier, about the interaction of the bird and the beetle, and print the contents of its assertion. Of course, you are not limited to simple text searches. The library has several search methods, including finding nanopubs with a given triple pattern — you can find detailed documentation here.
Hold on, I want to publish Nanopublications of my own!
To publish to the nanopub server you need to set up your profile. This allows the nanopub server to identify you. Run the following interactive command (on the command line):
setup_nanopub_profileIt will add and store RSA keys to sign your nanopublications, publish a nanopublication with your name and ORCID iD to declare that you are using using these RSA keys, and store your ORCID iD to automatically add as author to the provenance of any nanopublication you will publish using this library.
You can then publish a quick claim:
Published to http://purl.org/np/RA47eJP2UBJCWuJ324c6Qw0OwtCb8wCrprwSk39am7xckView the resulting nanopublication here. Note that the URI of your nanopublication is a signed hash of its contents, making its authorship verifiable and enforcing its immutability — known as a trusty URI.
Or, to leverage the true power of semantic technologies, you can build your own RDF graph of triples and publish that:
The above builds a graph containing a single triple that states (essentially) the concept pointed to by www.example.org/timbernersleeis of type Person. We use the rdflib library to build the graph, but this is already a dependency of nanopub. A Publication object is then created, using that graph as its assertion, and finally published using the NanopubClient as before. The code produces the following output:
Published to http://purl.org/np/RAfk_zBYDerxd6ipfv8fAcQHEzgZcVylMTEkiLlMzsgwQYou can view the resulting nanopublication here.
Outlook
nanopub makes interacting with nanopublications quite intuitive for those with sufficient RDF and python skills. For all others we foresee tools built around nanopub that make it intuitive for domain-experts (but not RDF-experts) to make use of the nanopublication network.
There are a couple of those already in the making:
- nanotate: Create nanopublications from annotations in PDF-files made with hypothes.is
- fairworkflows: Support the construction, manipulation and publishing of FAIR scientific workflows using semantic technologies. This is developed as part of the wider FAIR is as FAIR does project at the eScience Center.
Conclusion
The python nanopub library provides a high-level, user-friendly python interface for the nanopub server, making it easy to publish and search small scientific publications. We created this library to bring nanopublishing to python users and we’re keen to help people make use of it.
Consider how nanopublications might fit in with your field, and feel free to try the library out!
Acknowledgements
The quality of this text was greatly improved by the suggestions of Patrick Bos, Tobias Kuhn, Arnold Kuzniar, Lars Ridder, Pablo Rodríguez-Sánchez, and Stefan Verhoeven.

