Machine learning: when it is easy & when it is difficult
A crash course in machine learning; only high-school level of math is required before reading.
Machine learning (ML) is about having the computer learn how to convert input into output (or to make predictions), based on sample data, known as training data. In this article, I’ll introduce you to the basics of ML, and show you that, however, there’s more to it than having the machine learning it all by itself.
Let us start with the basic ML problem: classification. Imagine you have a lot of objects of the same type (data) and you want your computer to learn how to classify each object into good or bad. Usually you already have a lot of objects for which you know whether they are good or bad (“ground truth”) and you want to be able to predict for every new object that you come upon whether it is good or bad.
So far so good. For simplicity, it is convenient to imagine that you can represent each of your objects with two numbers (features, or variables), x and y. In real life the objects are much more complex than that (can you represent the content of an image with two numbers?), but for the purpose of explaining this is enough. This way every object is a point (x,y) in a 2D plane.
In the following plots, assume that your good points are the check-marks and your bad points are the crosses.

The problem of classification then becomes one of drawing a line (or curve) in the graph such that all good points are on one side of the curve and all bad points are on the other side. How difficult can it be? Here.

Congratulations! You have reached machine learning, level 0.0.
Let’s go to level 0.1. You want to try your fresh ML model in practice on new points. How well will it predict on new points? Suddenly, the new points are on the wrong side of the line!

What happened? You trained the model on too few data points. Or someone cherry-picked the points on which you train. Or you did not use a generic enough data-set for training. Anyway, after seeing the new points you wish you had used a circle instead of a line.

Or you don’t wish anything, because, remember, your data in reality is not a point in a 2-dimensional plane and you could not see that. If data objects were points in a 2-dimensional plane, there would have never been need for machine learning. In reality you need much more features to represent your data, but we cannot plot 10-dimensional plots.
Level 0.2 is when your good and bad points look something like this (but remember, you would not know that, because your data is not really in 2D).

Should I draw a line? Should I draw a circle? But then I have too many errors. (underfitting).

Are those points errors indeed or were they wrongly labeled in the first place by e.g. the lab staff? How am I supposed to know? How are the staff supposed to know, if they have to rely on lab technology for labeling?
Hey, should I draw a wild curve that splits all points exactly?
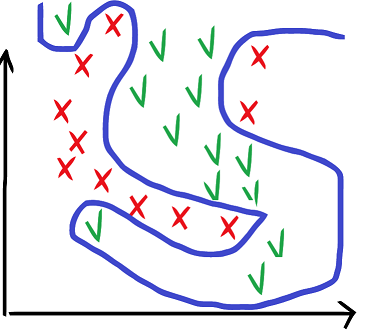
But how am I sure that the curve will split properly all new points that I haven’t seen, that it will not over-fit on the training data? I tried lots of methods (SVM, neural networks, random forests…) and still I don’t get good results on my test points, even though I kept some of the training data as a “control” dataset during training.
Wait. Why would I draw curves? Every time I have a new point for which I don’t know whether it is good or bad, I can just look into the neighborhood and label my point as the neighbors (“k-nearest neighbors method”).
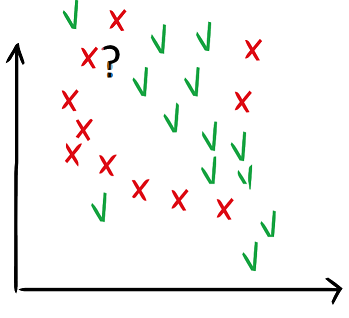
But how many neighbors should I look at? One, two, three? They all have different labels. And what is a neighbor by the way? Yes, in 2D it is easy but my points are not in 2D actually.
Wait, how am I sure that I chose the right features to represent my data? Maybe my data looks so messy because the features are not helping into classifying my objects in good and bad. Ah, what a mess, I should start all over with new features! Or maybe I should craft completely new features?
A-ha. Features. Why are we still talking about features when everybody knows that deep neural networks don’t need features? They take as input directly your data and learn everything by themselves. If you have enough properly labeled data, you barely need to do anything. Maybe you need to watch for over-fitting and under-fitting by using a part of your ground truth data as a control set, and tweak the hyper-parameters of the network, that is, the parameters that are not automatically learned by the network, until you get desired results. But that’s about it, it is all straightforward. Even the parameter tweaking is being automated nowadays. So, ML is easy again!
It used to be so, when all you were doing was classifying images. On the ImageNet dataset. On the input you put a picture of a robot or a man. On the output you tell the network what the picture is. In-between the network tries to adapt its “weights” by seeing many examples of robots or men and using calculus methods. Ultimately it finds which weights are best to go from a picture to a label with as few mistakes as possible.

That would be level 1.0. We opened a new chapter: deep learning.
Level 1.1 is when your input is not a picture or text, or anything else for which off-the-shelve neural networks exist. It is some kind of a special object of type X and there are no neural network architectures that can handle it.

What do you do? Do you try to convert your object into a picture, or a sequence, or? But then what is the best way to convert it so that the neural network can do its job? And what kind of neural network? And how do you best design this conversion, or features, for your neural network? Oh no, features again! Maybe I can try to design a new type of neural network to address my original objects of type X. You wish. That’s level 5.
Level 1.2 is when you are not trying to classify, but instead to map your input object to an arbitrary representation of it that suits your problem. From object X at the input to object X’ at the output. Lots of practical problems are of this type.

Then you need to figure out what the network should learn. It is easy when you classify, the network needs to learn the label good or bad. In the general case, learning to map from X to X’, you want the output to be as close to X’ as possible. Nice, what’s the problem? The problem is what you mean by “close”. We are back to the “neighbours” problem (see level 0.2). Remember, what works in a 2D space, does not work in an arbitrary space (in math, or ML, this is called “the curse of dimensionality”).
One can go to even higher levels, where the class of problems is different than classification or mapping from representation X to X’. E.g. when you try to generate new data that looks realistic (what do you mean by realistic, then?), i.e. deep generative models, or when you try to come up with a best automated strategy to achieve a goal, i.e. deep reinforcement learning.
There are many applications of neural networks and machine learning, and here we only scratched the surface. And we did not even touch unsupervised learning. See, here the learning was always done using some ground truth (supervised).
And, for sure, there is no upper limit on the number of levels!

