Machine Learning as a tool for political speech analysis
Femke van Esch, Sven van der Burg, Tejaswini Deoskar, Jeroen Snellens, Shoamu Tan, Erik Tjong Kim Sang
One of the main tasks of political leaders is to speak. Political scientists often analyze speeches in terms of their rhetoric and ability to impress the crowds. But speeches also have other functions: The speaker usually tries to help the audience make sense of the world (we refer to this function as puzzling), as well as to influence the actions of other political actors (we refer to this as powering). Understanding the powering and puzzling function of speech-acts can be as crucial as understanding political decision making.
Because speeches can have these effects on listeners, social scientists think of speech as a political act. Speeches can reveal how the goals of political actors vary, and how ways of going about reaching those goals differ from politician to politician. Analyzing speeches can also reveal information about what politicians find morally acceptable viewpoints or courses of action.
We can take the speeches of Russian President Putin concerning the invasion of Ukraine as an example. The powering parts of his speeches are often short and unambiguous: For instance, in the speech he held just before the (widely condemned) invasion, he warned anyone who tried to intervene ‘that Russia will respond immediately, and the consequences will be such as you have never seen in your entire history’. Though larger part of Putin’s speeches are devoted to puzzling, or meaning making. During these parts, he explains his worldview and justifies his actions. This part is of most interest to academics and policy makers. It can tell us what drives Putin, what his end-goals are, and helps us see evidence of miscalculation. By carefullly analyzing his speeches, we may be able to draw conclusions about other actions that Putin considers to be feasible, likely and legitimate.
To analyse meaning making, scholars in political, policy and organizational sciences can use the method of ‘Cognitive Mapping’ (CM). CM is specifically designed to identify argumentation, policy-goals, as well as causal and moral beliefs from speech-acts or text. CM focusses on the causal and normative relationships between concepts. By representing these relations in a graph (creating a semantic network), arguments that are found in a text are made explicit. This facilitates an in-depth narrative analysis of the meaning making embedded in the text or speech act. Researchers may then use graph-theory and network analyses techniques to quantitatively analyse viewpoints in a cognitive map, which allows researchers to compare different texts or speeches to each other.
While the method is a powerful technique for scholars in various domains of social science, it has a major drawback: It still relies on the hand-coding of texts. In the Small-Scale Initiative in Machine Learning project we engaged in with the engineers of the Netherlands eScience Center, we set out to use state-of-the-art machine learning techniques to automate the annotation necessary to apply CM to the data.¹ Apart from speeding up the process, this increases the reliability of the technique.
The following example of a sentence from Putin’s invasion-speech may clarify what CM annotation of texts involves: ‘The purpose of this operation is to protect people [Effect] who, for eight years now, have been facing humiliation and genocide perpetrated by the Kiev regime. To this end, we will seek to [Causal Link] demilitarise (Cause A) and de-nazify (Cause B) Ukraine, as well as bring to trial those who perpetrated numerous bloody crimes against civilians [Cause C]’. This example also provides a first indication of the complexity of our research goal, as it shows that:
- Each of the three parts the causal relation may correspond to a multi-word phrase in a text;
- The three parts may appear in different orders in the text;
- A causal relation may cross sentences.
Using existing CM data from a previous project on the meaning making of political and financial leaders concerning the Eurozone crisis, we set two initial aims for our project: To identify sections of text that contain causal relations and to identify the causal triplets of cause, causal link and effect. For both tasks we used several easy to implement, state-of-the-art machine-learning methods.
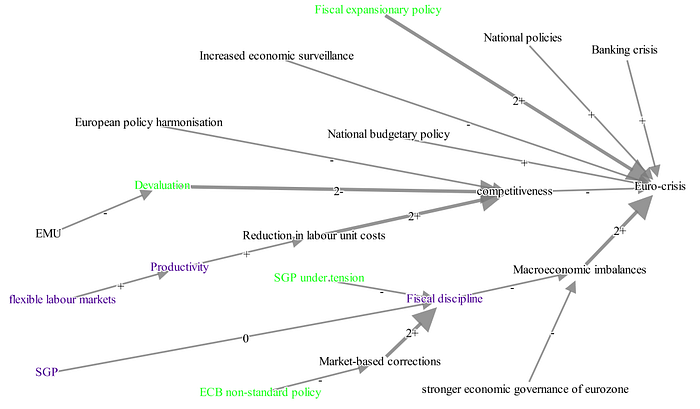
We focused on deriving causal (rather than normative) relations from text, because the method is much more complex than existing automated text-analysis techniques. The causal relations that make up the core of the CM technique consist of three parts: The cause-concept, the effect-concept and the phrase or word (often a verb or conjunction) indicating that they are related and in what way (positively or negatively). The outcomes of our project confirmed our expectation that automating CM is a difficult machine learning task: the predictions from the mchine learning models do not come close to the labels given by the human coders.
Still, there are plenty of reasons to be optimistic about our results: Both the models we developed for the causal relation presence detection and the causal relation tagging tasks could be quite useful despite producing false positives. Evaluation of the outcomes showed that it is quite easy for a hand-coder to recognize and dismiss them. The models may thus be used in a so-called ‘human-in-the-loop’ pipeline in which the ‘machine’ identifies causal sections or relations in the text that are subsequently checked and corrected by a human coder. These corrections could then be fed back into the model to improve its learning.
We also found that especially the semantic role labelling method in combination with manually written rules seems promising in the causal relation tagging task. We also used relatively strict evaluation criteria for this project. Compared to other widely used automated methods in the field of political science, for example, our results are actually comparable. We are currently further exploring the potential of a rule-based model.
Although we did not fully solve our research problem in this project, participating in the Small-Scale Initiative in Machine-Learning yielded promising results which culminated into a new research question guiding the next stage of our project. Our research team had only a basic understanding of machine learning before the start of this project, and the support offered by the engineers of the eScience Center has been invaluable to reaching the next stage of our project This allows us state with confidence: To be continued…
This blog is part of our blog series: The Small-Scale Initiative on Machine Learning, how did it go?, where groups who were invited to participate in a project with eScience Center Research Software Engineers write about their projects and their experience.
1. Read a full report of the project here.
