Machine learning for research — use it or refuse it? Two flowcharts to help you decide.
Machine learning (in particular deep learning) started to become extremely hot 5–10 years ago. Now, this trend has fully reached most academic fields outside computer science as well. But will it also help you with your research question?
Clearly, machine learning is a broad and complex field. So there is no simple answer to whether it makes sense to aim for applying machine learning for your specific problem. If you have never applied machine learning tools yourself, honestly, the best you can do is grab your data and your research question and sit together with someone with plenty of hands-on experience in machine learning, preferably on related topics (or join events such as this one). But if you don’t have the luxury to know such a person, try this short guide (and better not what you see in the cartoon below).

Part 1 — Is it worth considering?
To start, try getting a clear idea of what a machine learning solution would have to achieve. Then go through the flowchart below.
Machine learning models can fail in unexpected ways
The clearest answer I can give is when you come with a mission critical task. That’s essentially anything that should never go wrong and where no final human inspection takes place. In those cases: forget about AI. Sure, there is autonomous driving, clearly a mission critical application. But AI systems failing in unexpected ways have drastically reset expectations in that area (see this blog post or one of mine on the same topic). So, that’s only confirming my point: don’t use AI for it.
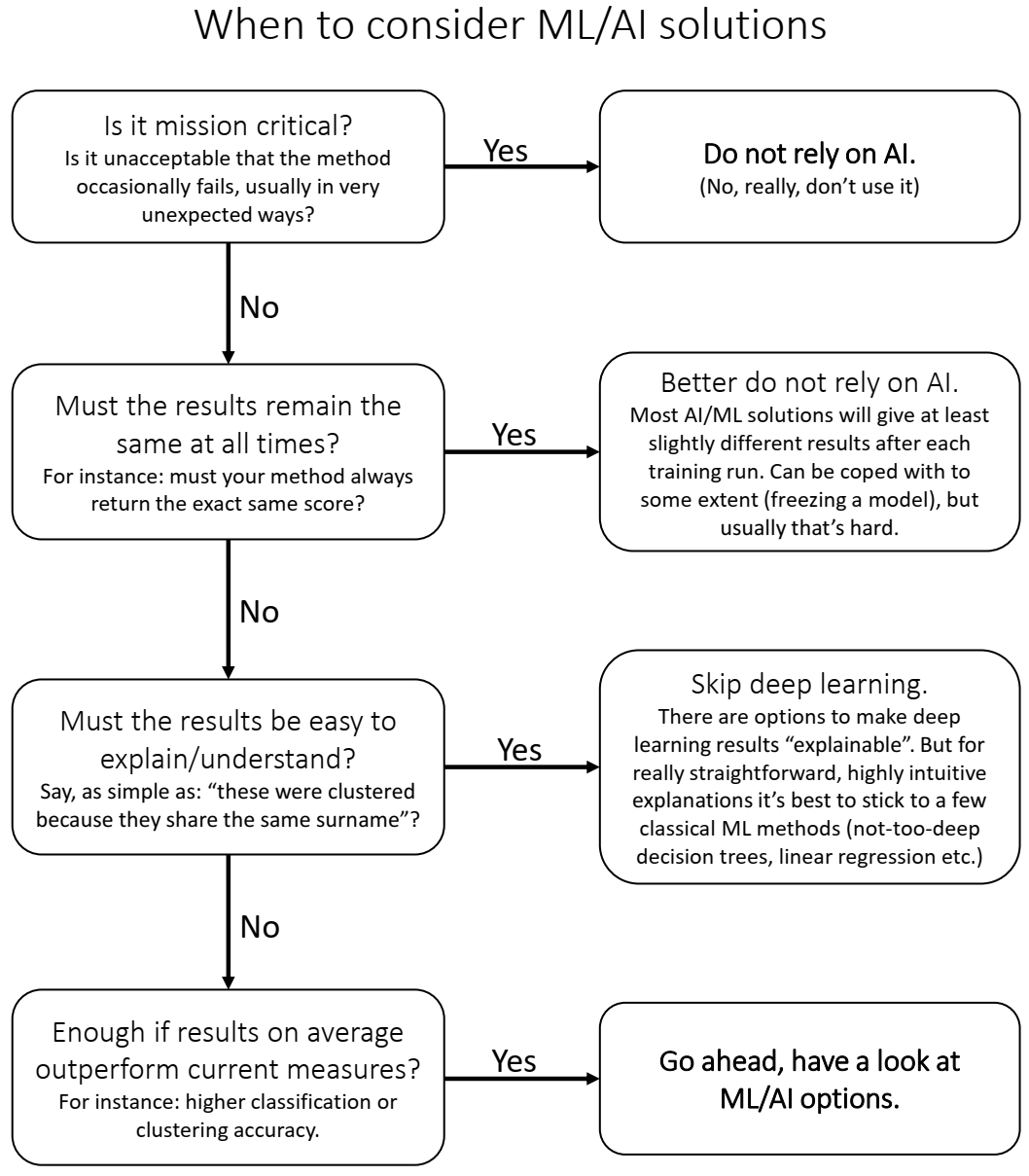
Must the results remain the same at all times?
Think for instance of a distance measure used for clustering. Classical measures for this (cosine, euclidean etc.) will always return the same values, now and in hundred years. In contrast, many machine learning solutions are moving targets which involve training a model on a given dataset. Say, your model outputs a distance value for two inputs, classifies an input, or clusters a set of inputs. In all such cases the outcome can change each time the training dataset changes. Even worse, unless you take extreme care, the results will even be slightly different each time you train a model on the same data (shocking, isn’t it!? read more here). You can still make things more reproducible, for instance by doing a proper versioning of your trained models. But better don’t think in terms of hundred years.
Must the results be easy to explain/understand?
Many people interested in machine learning will have heard about the “black-box problem”, which usually refers to the fact that the model outcome cannot easily be explained due to the high model complexity. To get this right out of the way: Even the fanciest deep learning networks are not truly black boxes, because each mathematical operation done to get a certain outcome can in principle be accessed. The key problem actually is that it’s extremely hard to translate this into an understandable pattern. So, if you want an explanation as simple as “A is close to B because the euclidean distance is below x” then deep learning is usually not the route to go (unless, maybe, you really know a lot about explainable AI). Some classical machine learning techniques might be worth considering here, because techniques such as decision trees or linear regression models (on reasonable number of features), usually do provide very human-accessible explanations.
Good enough if results (on average) outperform current measures?
Finally, if what you really want to achieve is mostly to outperform current techniques, things look different. Say you want to get better query results than before (but a human in the end would anyway inspect them), or you want to classify things with higher accuracy (failing occasionally is fine though), or you want better predictions than you currently have (as all predictions those are allowed to occasionally fail as well, just maybe less often). In such cases, machine learning is probably worth considering.
It is important to notice that this point of “outperforming current measures” is broader than only achieving higher accuracy. Often machine learning can also provide faster, more scalable solutions. In big data times, that can make a huge difference.
Part 2 — Will it make sense for your particular problem/data?
Now we reach the difficult part.
If you have never applied any machine learning yourself, this seems near-impossible to answer. The second best thing you can do (first best thing again is: talk to someone experienced with machine learning!), is to search for related work where machine learning was applied. This is tedious, and you might have to dig your way through mountains of jargon and unnecessarily complex and incomprehensible papers. Going through this pain, however, will hopefully give you a more realistic picture of what you can obtain with the type and amount of data you have. Otherwise, those incredibly shiny results that make the headlines can easily cause unrealistic expectations. As an orientation, have a look at the flowchart below:

If you are serious about using machine learning for your research — maybe you are applying for funding, or deciding on future steps in you project, or looking for new collaborations? — better spend some time to gain a basic intuition on how machine learning could help with your problem. Don’t worry, you don’t have to become a machine learning expert yourself, but I imagine you also don’t want your next proposals to sound like this:
“We have data (or hope to have it), and then we want to do magic (which we simply call deep learning).”
A little magic at the end
OK then. No magical solutions from deep learning. Still, I am convinced that there is plenty of opportunity to enhance scientific research through machine learning.
Yes, it can be hard to do right.
And no, it is no silver bullet.
But it is a whole lot of fun to do! And even if it doesn’t achieve what was hoped for, it will give you new insights about your data and your research question.
And sometimes… well… sometimes… there are those rare moments when you press enter and then start to see this magical glittering that seems to come from your screen.
Get in touch
I hope you find this quick guide helpful. If you do, please share it, clap for it, or even better: use it for your upcoming machine learning journey!
And get in touch if you have any comments or questions.
If you are based at a Dutch research institution and have a research question where you have hope that machine learning could help improve things, speed up things, or give access to bigger datasets, but feel that you need additional feedback on your ideas: feel free to get in touch with the machine learning team at the Netherlands eScience Center: machine-learning@esciencecenter.nl
You also find me on twitter: me_datapoint
Special thanks to Patrick Bos, Sonja Georgievska, Tom Bakker, Carlos Martinez-Ortiz and Pablo Rodríguez-Sánchez for helpful comments and discussions.

