Literate Programming in Science
1. The Why
Literate programming /ˈlɪtəɹət ˈpɹəʊɡɹæmɪŋ/ (computing) Literate programming is a programming paradigm introduced by Donald Knuth in which a program is given as an explanation of the program logic in a natural language, such as English, interspersed with snippets of macros and traditional source code, from which a compilable source code can be generated. Wikipedia
Ever since the introduction of computers into the realm of natural sciences, software has been slowly replacing pure math as the main driver for advances in methodology. While it is considered to be absurd to write a paper in physics for instance without any equations, the same cannot be said for writing papers without code, weather it be ecological models, physics simulations or climatology. The accepted standard is that models are described in equations and some fancier algorithms possibly in pseudo code.
Literate Programming is an ancient art form. Maybe some older programmers would be insulted by calling something from the 80ies ancient, but what I really mean is that Literate Programming is a form of teaching. You simply explain, in words, what it is you’re doing. In that sense, Literate Programming is a method of communicating that should be at the heart and soul of every scientist that dallies with the computational aspects of the job. The arguments that I bring forth here touch upon the very foundations of what it means to do science.
There are many arguments why or why you should not use Literate Programming when developing software. Many developers have learned how to think in terms of code. Good code should be self-explanatory, they say. And in a way, I agree: good code should be self-explanatory. Not every line of code should need explicit regurgitation.
However, there are some major problems with this philosophy, if one might call it that. Did you ever wonder why it is that you learned reading before writing in literature, but not when it comes to computer programs? Sure, we learn the alphabet to start writing and reading, but to really write a coherent well structured story or essay? I’d say that happens roughly a decade after the ABC. With software however, it sometimes seems to take more effort to read a program than to write one. Why is this?
- Hierarchy: Many code bases are hierarchical. A generic function might be defined only for very specific use in the code, or for many different uses. There have been some suggestions of writing
ARCHITECTURE.mdfiles to go along with a package. - Abstractions: The code itself doesn’t encode the purpose behind it, only its function. This point bugs me to no end, maybe because I’m a trained physicist and not a mathematician? Many functions in a more complex code base deal with abstract quantities. It is considered a good practice to keep functions abstract so that they can be reused even if the circumstances are slightly different. It may turn out that our most generic defenition was not up to the task for our specefic case. As a result we may tweak the implementation or even the precise outcome of the function. What we are left with is called a leaky abstraction. To figure out why a function is implemented the way it is, we may need to know about its purpose elsewhere in the code.
- Intended use: in an ideal universe, intended use shouldn’t matter. Every unit of code is an island universe onto itself. But we all know that most code is far from ideal.
Or maybe it is because we tend to underestimate the amount of effort that goes into writing a truly well written piece of software, and compared to natural language, we’re all still stuck in kindergarten?
To be clear, we are not contending the well accepted use of API documentation or tutorials. We should accept it as canon that those are very useful indeed. The difference is that those document the intended use of a library, following a strict client-server protocol. One person serves the software, another uses it as dictated by the prescription. While this may be the case in industrial software development, in science things are a bit different.
Why scientific software is different
Please forgive me for taking the easy way out, and arguing only for the use of Literate Programming in science: the argument is so much easier to make. There are several good reasons for this:
- In science, the division between software developer and user is not so clear cut. The developer and user ofter are the same person, leaving out an important quality control.
- In science, code has meaning: a variable is not just container for a 64-bit IEEE 754 floating point value, this value describes something, has units, a physical interpretation. A variable can often be linked to a physical quantity that needs elaboration elsewhere in the text.
- In science, it is often hard enough to reproduce results, even with the same data. People make mistakes, or with deadlines approaching, shove things under a very bumpy carpet.
- In science, it is common enough to include equations in journal articles. These equations help other scientists convince that you worked really hard and that the subject is no trifle. At the same time, including bits of code is often a bit frowned upon. At the very best, to describe an algorithm you may include a piece of pseudo-code of which the semantics is some ill-defined form of Matlab. How do you even test pseudo code?
- Scientists are not professional developers. We need more conduits to permeate best practices. Literate programming stimulates other people to actually read your code, while you’ll have an easier time reading other people’s code. This interaction should make better programmers of all of us.
Scientific works are supposed to be held to exacting standards. These standards are upheld by systems of peer-review and demands of precise reporting of methodology. These standards are often surprisingly lax when it concerns the use of software. This problem is for a large part addressed by the “Open Science” movement in general, stimulating the use of open source software in science. Still, even if code is open source, this does not mean that this code can be easily understood.
21ˢᵗ Century science
Ok, I’ve shown you the deepest pits of hell. Things aren’t all that bad, are they? There are some good initiatives in the Open Science movement. There is the Journal of Open Source Science that lets you publish your software. Also, there is an emerging practice of publishing your analysis pipeline in Jupyter notebooks on Zenodo. This is the absolute best you can hope for at the moment: kneel down on your bumpy carpet and praise your favourite deity!
What I’m saying is: this is not nearly good enough. All these solutions have seperate places for the scientific results and the code that produced them. As if the code is an ugly duckling that needs to be hidden from ignorant eyes. In a way these solutions are still holding to an old fashioned way of publishing on paper, with tight page limits. And I get it: science is tough. Tough enough without me bickering about transparency and reproducibility.
Then, what are we aiming for? We need to move scientific publishing into the current century: the century of Wikipedia and Github. Scientific information need not be bound to bundles of papers of decreasing length. We are building a trinity of data, code and knowledge.
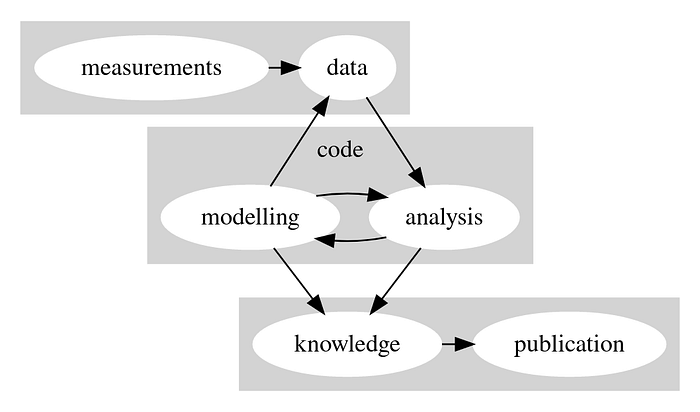
Some would say code is data, which is true on a certain level, but what I mean by data is things that are measured in real life, or outcomes of previous computational experiments. Scientific data is stored in huge databases that are often publicly accessible. We have seen the movement of making data FAIR, Findable, Accessible, Interoperable and Reusable, and in general people have gotten the idea (I know, wishful thinking).
FAIR Software?
Then there is code: by now most funding agencies agree that scientific results should be produced with open source software. What no one agrees on, is what this should mean: sure, your code needs to be accessible somewhere, and have a license. Do we get penalized if we write bad code? Is the paper rejected? I’m digressing. Attempts are underway to define what the FAIR principles would mean in the case of software: see for instance https://fair-software.eu/.
When it comes to scientific software, each package falls in roughly one of two categories: modelling and data analysis. While many scientists do a bit of both, these different categories require a different approach to development and especially documentation.
Notebooks
Analysis pipelines are often developed inside real-time environments like Matlab, RStudio and Jupyter (is this wishful thinking again?). These tools generally allow for a limited form of literate programming in the form of notebooks. Yes, notebooks are great for rapid development and data exploration, but they come with a few downsides: they don’t support the noweb syntax for decomposing codes into didactictally advantageous chunks, order of evaluation is generally not fixed, and they don’t work well with compiled languages. Jupyter Notebooks can be exported to Markdown, offering an easy transition from a “live” development stage to making the analysis ready for publication. RStudio offers a (almost) complete solution here with RMarkdown. In past and future blog posts, I argue that Entangled offers a more generic method for Literate Programming, ideal for writing reports and papers.
Modelling
Where I think Literate Programming really shines, is in scientific modelling. When it comes to modelling, the code really is an extension of what you can do with mathematics. Writing a code helps you understand a system. The code is not just a translation of a model such that the computer can execute it. It is also a rigourous encoding of the model itself. We cannot mince words about what we’re doing: the code is absolute. This is exactly why we traditionally use equations to communicate the more exacting parts of our work.
I have worked out several examples that show how nicely equations and code mix when it comes to physical modelling:
- LiteratePT (https://jhidding.github.io/literatept/) is my translation of Kevin Beason’s SmallPT 100 lines of C++ global illumination ray-tracer into Rust. It was a fun puzzle to figure out how this code really works!
- Chaotic Pendulum (https://jhidding.github.io/chaotic-pendulum/) is a demonstration of PureScript to model a chaotic double pendulum.
- Adhesion model (https://jhidding.github.io/adhesion-code/) part of my thesis work, this C++ code uses CGAL (https://cgal.org/) to compute large scale structure of the Universe.

Some concerns, some chances
Maintenance
Talking to computer scientists, the major critique of Literate Programming in general, is that it hurts the maintainability of the code. While the code is excellently documented, it can be very hard to navigate the functionality of the code from a software architecture point of view. This is where Entangled comes in. Entangled makes it possible to edit the code both from the original Markdown as well as the generated source code. We can have the best of both worlds. Debugging and maintenance is done as before in the traditional way. Refactoring code sometimes actually becomes easier, since code can be moved around by changing a few directions in the Markdown files.
Hybrid styles
Every code contains boilerplate. It becomes a matter of taste how to deal with this in the context of Literate Programming. You don’t need to put everything in a literate style. It is perfectly possible to leave boilerplate code in normal source files.
Layered programming
Literate programming techniques also offer new paradigms for development. One such paradigm is layered programming. In this approach you can structure a code not just in modules but also in layers, each layer being a separate chapter or section in the literate code, while the modules organize the code in a traditional manner for the compiler. This gives an extra option for seperation of concerns, the code now having a two-dimensional organisation structure. One immediate example that comes to mind is the building of a command line tool with multiple sub-commands. Each command shares the same structure but adds different functionality. In a more scientific setting, this could be a model with increasing levels of complexity. Each layer may touch upon every part of the code, adding functionality to many different modules.
Conclusion
To conclude, Literate Programming can solve some real problems in the realm of Research Software Engineering and our means of publishing about software in science in general. Jupyter notebooks go a long way, but to my taste not far enough. The main reason for this is that scientists are not aware of the possibilities, while for computer scientists Literate Programming is something of a past station, of which the usefulness is debated.
It is high time that we identify areas where Literate Programming maybe has little added value, and others where it works great (there are plenty: did I mention writing tutorials?) Meanwhile, we need to improve our toolset (Entangled is not perfect yet), and develop a set of best practices when it comes to Literate Programming.
About the author: I’m (among other things) the developer of Entangled, a Literate Programming framework and toolset. The main goal of this blog-post is to convince you that Literate Programming is a good idea in the first place.

