Highlights from the European Conference on Machine Learning 2019
ML highlights and trends as seen at ECML-PKDD 2019 (16–20 September, Würzburg, Germany)
The conference’s cryptic name is due to the fact that it is a merger of two conferences: the European Conference on Machine Learning (ECML) and the European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD). I mostly attended for the machine-learning part, so I will focus in this blog post on the ML aspects of this one-week conference.
Let’s start with my personal highlights…

Highlights (my subjective choice, obviously)
Having more than 170 contributed papers is still not a guarantee for finding outstanding advances of the field. Luckily, I came across quite a few very promising contributions at ECMLPKDD 2019. Besides some really interesting real-life use-cases (some mentioned further below), here my personal highlights that really felt like considerable steps forward.
1 Deep network training using random learning rates!
This is really cool! The authors found a way to largely avoid learning rate optimization altogether. On a wide range of test cases their algorithm (Alrao) performed as good as stochastic gradient descent with optimally tuned learning rate.
Paper: https://ecmlpkdd2019.org/downloads/paper/805.pdf
Code: http://github.com/leonardblier/alrao

2 Novel faster and more accurate time series classification methods!
In his keynote lecture, François Petitjean presented two novel tools. The first is a more classical tree-based approach called TS-CHIEF, which on more than fifty test datasets on average performed as well as the current state-of-the-art method (HIVE-COTE) while training and scaling vastly faster.
Paper: https://arxiv.org/abs/1906.10329
Code: https://github.com/dotnet54/TS-CHIEF

Then, together with Hassan Ismail Fawaz and others they just published a deep learning approach for time series classification on arXiv. Their network architecture is largely inspired by Inception CNNs known from computer vision. No surprise they termed it InceptionTime. Roughly performs as well as the aforementioned method but both approaches seem to outperform each other on different datasets. Which is cool because that means that they focus on different aspects of the time series. I wonder what happens if you ensemble both, TS-CHIEF and InceptionTime…
Paper: https://arxiv.org/pdf/1909.04939.pdf
Code: https://github.com/hfawaz/InceptionTime
Related to this, the authors also recently published a very thorough review article on deep learning for time series classification.
3 Faster, tunable t-SNE!
I guess few tools are more common to data scientists than t-SNE. It’s used to break down abstract feature vectors (or latent representations) into low dimensional plots (LINK).
Here, the authors not only found a way to get a much faster (python usable) implementation, they also discovered that varying one specific factor in the t-SNE algorithm (that so far was fixed to 1) can be used to fine tune the clustering strength.
Faster t-sne implementation: originally here: https://github.com/KlugerLab/pyFIt-SNE
Alternative version is opentsne: https://github.com/pavlin-policar/openTSNE/
Paper: https://arxiv.org/abs/1902.05804
Code: https://github.com/dkobak/finer-tsne
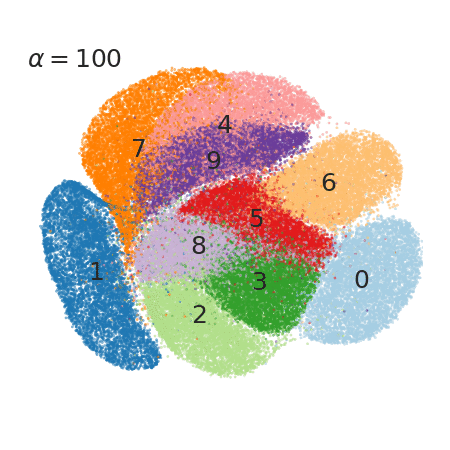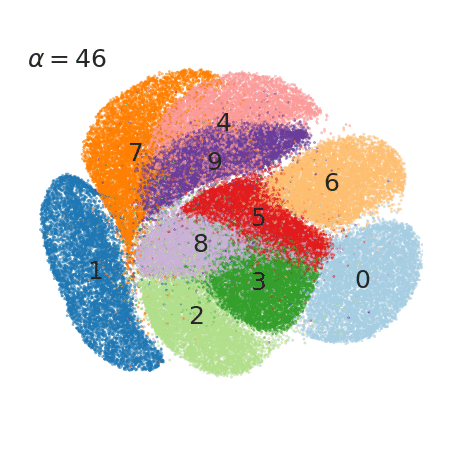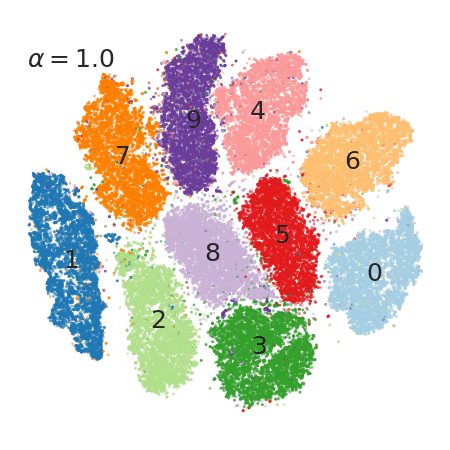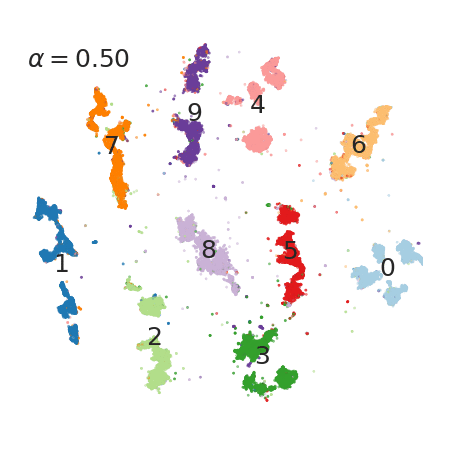
4 Novel reinforcement-learning algorithm based on an actor and several (off-policy) critics.
They call it BDPI (Bootstrapped Dual Policy Iteration) and it seems that their approach it unusually stable as well as robust to hyperparameter variations, both being huge obstacles in many RL use-cases.
Paper: https://ecmlpkdd2019.org/downloads/paper/48.pdf
Code: https://github.com/vub-ai-lab/bdpi
5 Autoencoder with agnostic feature selection
Guillaume Doquet and Michèle Sebag presented an autoencoder combined with structural regularization for better feature selection (or agnostic feature selection, hence the name AGNOS). It indeed performs pretty well (unfortunately computational cost increase quite a bit).
Paper: https://www.ecmlpkdd2019.org/downloads/paper/744.pdf
Code not available yet.
Other trends and common themes
Probabilistic models
What people in machine-learning mean by probabilistic models is usually models that not only output a single prediction, but also give a distribution or other measure for how certain the model is about its prediction.
Back in the older times of ML (which in ML means a few years back), most ML practitioners would be happy enough to have a model that performs decently with respect to its output accuracy. To estimate the certainty of those models, it was often common practice (which means it in many cases still is!) to simply look at the model predictions one layer before the final argmax and treat those values as probabilities. But although a softmax layer will indeed give probability-like looking values (they are properly normalized to a sum of 1), they are usually not very reliable uncertainty estimates.
ECML-PKDD2019 hosted two entire sessions on probabilistic models with a very strong focus on Gaussian processes. There was, for instance, an interesting implementation by Wistuba and Rawat using a “Large Margin Gaussian Process” that can be added to the end of a conventional CNN. Or a promising looking deep constitutional Gaussian process method by Blomqvist et al.
Algorithm benchmarking vs. real-world usability
This is not exactly a new trend. But you could say it’s a remaining theme. The ML field is no different than most scientific domains in that it is highly driven by the “publish or perish” paradigm. You want to stay in academia? Better publish as much as you can!
So no surprise that at ECML-PKDD2019 I saw what also can be seen elsewhere: Most papers coming out in ML represent — at best — incremental improvements over previous work! Often that means a slightly better benchmark here, a little faster computation there. That’s fine of course. Only that for people like me that are mostly interested in applying ML tools for a wide range of real world problems, those incremental changes rarely justify going through the hassle. The projects I work on are scientific research projects. For those, I would nearly always favor a more-established, better documented method that gives me a decent accuracy over a newly developed one that might give me slightly better results, but is either more cumbersome to implement, or that requires more expertise to properly tune and understand.
Resource-efficient deep learning (and ML)
Often motivated by limited computational resources of devices (IoT, smartphones etc.), sometimes also motivated by energy efficiency/sustainability aspects, efficient machine learning algorithms have gained quite some traction.
Typical tricks include network pruning (creating sparser models), or lower precision values (e.g. gradients), for instance by going from floats to bitsets.
Another approach is cleverly designed network architectures that allow to drastically cut down training cost for large ensembles of networks. The well-known Inception architecture for CNNs could be seen as such a case. Dimitrios Stamoulis (Carnegie Mellon, USA), for instance presented a new efficient method for neural architecture search.
Closely related, there was also an entire workshop on green data mining.
Explainability, Interpretability
Not unexpectedly, explainable AI or model interpretation came up at many points during the conference. The keynote by Tinne Tuytelaar (KU Leuven, Belgium) on computer vision discussed this to quite some extent. And on the last day there was an entire tutorial/workshop session on the topic → see AIMLAI-XKDD website
The slides of the XKDD tutorial part are also all available online: https://kdd.isti.cnr.it/xkdd2019/pkdd2019xkdd_tutorial_last.pdf
Use of ML all over the place
Again, no new trend. But it remains great to see, because in the end this is what all of this is about (for me at least). And that’s the use of ML techniques over a wide range of fields and topics.
Obviously there were many of the usual suspects: analysis or prediction making in finance, e-commerce, power consumption, public transport usage, etc. Closer to my heart though, were the many nice examples of different scientific disciplines using ML to help analyze and interpret their data. I attended a cool workshop on machine-learning and music, looking at neural networks generating human-resembling sheet music or reading ancient hand-written sheets.
I also greatly enjoyed the keynote on “palaeontology as a computational science” by Indrė Žliobaitė, and saw plenty of interesting cases from life sciences and social sciences.



