ESMValTool: Recipes for solid climate science
This story was coauthored by Peter Kalverla and Bouwe Andela
Like an artisan chef can improvise a delicious meal, so too can a scientist create new insights from raw data and exploratory analysis. But to run a successful restaurant with personnel and a consistent menu, our chef resorts to writing down his recipes. Similarly, we scientists must make an effort if we want our results to be consistent and widely reusable.
This is where ESMValTool comes into play. Designed to ease and automate the analysis of large ensembles of climate model outputs, ESMValTool defines a clear and plain scientific “recipe” format. This not only helps to make workflows scientifically robust, but also provides a way to easily share and build upon each others’ work. Even if you’re not a climate scientist, there are valuable lessons to draw from ESMValTool’s approach to FAIR and open science.
In this blogpost, we’ll explore four aspects of ESMValTool that may be worth your while. Starting with its take on analysis-ready data and its rich suite of pre-processor functions, we’ll set the stage for a broader discussion on how standardization helps making research easy and FAIR and the crucial role of a community in setting itself up for success.
Analysis-ready (CMIP) data
Strictly speaking, most of the functionality described here is part of ESMValCore. ESMValCore is the engine, if you will, that executes ESMValTool recipes under the hood. ESMValTool, then, is a big collection of recipes. To the user of ESMValTool, this distinction is irrelevant, but we’ll use the terms interchangeably to be as accurate as possible. For a description of ESMValCore as a standalone utility, see the companion blogpost.
ESMValTool was originally designed for the analysis of CMIP data: output of many climate models assembled in a series of “Coupled Model Intercomparison Projects”. The CMIP data request specifies standards that the data should adhere to. Known as the CMOR standards, after the “Climate Model Output Rewriter” software, they describe things like variable names, units, coordinates (with their direction), and also file name conventions. These standards make it much easier to compare output from different climate models, and they are the foundation on which ESMValTool & Core were built.
For example, the file name conventions make it possible to specify a dataset like so:
Dataset(
short_name = 'tos',
mip = 'Omon',
project = 'CMIP6',
exp = 'historical',
dataset = 'CESM2',
ensemble = 'r4i1p1f1',
grid = 'gn'
)and ESMValCore is able to locate it, both on your local computer or on ESGF, the shared infrastructure where all of the CMIP data are collected. ESMValCore can automatically download data from ESGF, provided that the data is present there.
Pause a moment to let this sink in: ESMValCore eliminates hardcoded paths in your scripts, or rather, recipes. This is key to making them interoperable.
If you’ve worked with CMIP data yourself, you’ll probably know that, despite the strict protocol, small dataset issues are commonplace. That’s why ESMValCore executes an additional CMOR check upon data loading. Where possible, it applies automatic fixes for known and trivial issues. This makes working with the data much easier.
Another common issue with CMIP data is that files may not or no longer be available. ESMValCore makes it easy to perform wildcard searches or ignore missing datasets, saving you the trouble of figuring out which datasets are available or have been retracted since the last time you ran your recipe. Thus, ESMValCore is also a great utility for CMIP data discovery.
While ESMValTool & Core were originally developed for CMIP data, it also supports ingestion of other datasets. For example, it can apply “on the fly CMORization” of ERA5 data, and it ships with download and “CMORizer” scripts for many other (observational) datasets. This makes ESMValTool more broadly applicable and moreover, it promotes standardization beyond its original scope.
To summarize, ESMValTool makes it easy to get to your data. In the next section, we’ll describe how ESMValTool also helps to standardize how you process it (without compromising on versatility).
ESMValCore’s rich preprocessor suite
Like with a kitchen recipe, after the ingredients come the preparation steps. In ESMValTool & Core, they are called pre-processors. Common preps for climate data include regridding, area extraction, calculating anomalies and all kinds of statistics.
ESMValCore has built-in functions for each of these pre-processors, and they can be added to a recipe using a very high-level specification. For example:

By reading this snippet, you can probably get a pretty good idea of what this recipe is trying to achieve: the mean (temperature) change over Europe with respect to a reference period. This is a declarative syntax, focusing on what should be done, instead of how.
Of course, it can be very valuable to have a good discussion on how something should be done. But for most practical purposes, it’s often convenient to skip these “implementation details” and focus on the intention. Moreover, a standard way to do things makes it much easier to compare results and also to optimize the performance.
Ideally, with ESMValCore, the standard pre-processors provide a scientifically sound consensus implementation. For example, it uses state-of-the-art regridding with ESMF/ESMPy, and strict CF-compliant statistics from the Iris package. These functions have been designed by domain experts and are openly developed, so anyone can suggest improvements if they feel the current implementation is insufficient. ESMValCore executes these steps in a standard order which makes sense for most applications. However, you can also specify a custom order as this might make sense for some specific use cases.
In the illustration below, you can see the default order in which the pre-processors are executed. In your recipe, you can simply select those steps that are relevant for your workflow.
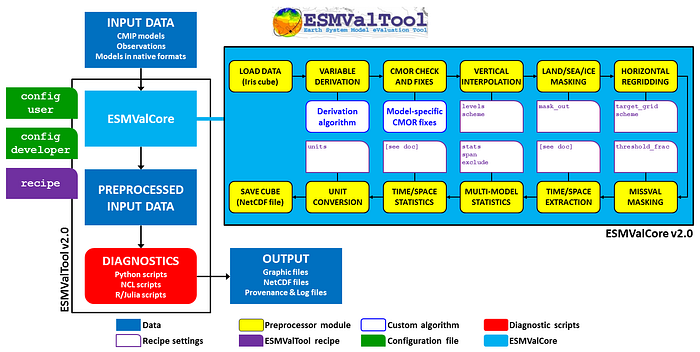
After prepping, your data is (optionally) passed on to a diagnostic script. This is the place where you can do custom things, such as making a figure, or doing a more thorough and case-specific analysis. “Combining the ingredients into a tasty dish”, to stick with the chef’s analogy.
So far, we’ve seen how ESMValTool tries to streamline those parts of your analysis workflow that can be standardized, and tries to accomodate all specific things you might need or want. In the next section, we’ll see how this helps you make your research more FAIR.
FAIR and open science
ESMValTool is a great example of how open science can work in practice.
Recently there’s been an increased focus on accessibility, transpancy, and reproducibility in science. We’ve seen the advent of open access publications, the introduction of FAIR standards for research data management. It’s easy to extrapolate these ideas to other aspects of the research process as well. At the same time, this can be daunting, because it may seem like a lot of extra work that you might not have the time or skills for. So let’s see how ESMValTool helps with these concerns.
One ideal that’s often associated with open science is reciprocity, which we all know in lyrical form as “never take more than you give”. The idea is that scientific progress benefits from mutual exchange and building upon each other’s work. ESMValTool provides a platform for receiving and giving back. By making available a large suite of recipes that other people have already composed. By establishing a process to contribute your own recipes. By setting a standard format to encode recipes. By integrating existing functionality into a streamlined workflow system. And by facilitating a process of feedback based around users’ contributions, and a forum for discussion. Many of the things that are hard to organize on your own, have already been organized by the ESMValTool community. Thus, you’ll be greeted with a warm welcome instead of a daunting prospect.
Going more into the specifics of FAIR, we can see how ESMValTool contributes: ESMValTool has great documentation listing all available recipes and a gallery with outputs. You can also list the available recipes from within the software, or browse the source code. So recipes are quite findable, although you could still take it a step further by creating a searchable registry with unique identifiers for each recipe (Note that the package as a whole does have a DOI for each version).
ESMValTool recipes are also very accessible. The YAML format is very readable for humans and also by machines; they can be executed. As we’ve seen above recipes are also portable: hardcoded file paths et cetera have been eliminated. For each release of ESMValTool, all recipes are executed to see if they still work, and output is made available.
To summarize, ESMValTool itself would qualify as “FAIR software. But moreover, ESMValTool recipes also come a long way as “FAIR scientific workflows”. Just like kitchen recipes empower chefs, ESMValTool recipes empower scientists.
The crucial role of community
ESMValTool would not have been where it is now if it wasn’t for the community. The ESMValTool community is a nice and welcoming crowd of scientists and software engineers from various institutes in Europe and beyond. In addition to lively interactions on GitHub there are monthly online meetings that are open to all, and there’s an in-person workshop once or twice a year. Furthermore there are spontaneous gatherings of ESMValTool contributors at other ocassions such as conferences.
Over the years the ‘core team’ has gained a lot of experience and become more professional, for example when it comes to processes for decision making and user engagement. There are clear guidelines for contributing to the codebase, and people are always willing to help each other out. To support new users, the user engagement team maintains a tutorial that is regularly taught.
By fostering enjoyable and personal interaction, the community plays a vital role in facilitating the development and long-term sustainability of ESMValTool.
Conclusion
In conclusion, ESMValTool provides a valuable platform for scientists to achieve consistency, reusability, and standardization in their research, owing much of its current success to the dedicated community that surrounds it.
Are you a climate scientists and do you want to be part of this community? Don’t hesitate to reach out on GitHub or another channel that you see fit. Are you passionate about open science but not necessarily in climate science? Then we hope you could get some nice takeaways from ESMValTools experience and we are always happy to exchange more. In any case, the next time you visit a restaurant, remember to appreciate not only the chef but also the thoughtfully curated menu.

