Analysis-ready climate data with ESMValCore
The “Easy IPCC” blog done differently
Co-authored by Bouwe Andela
In a recent blog post, Tom Nicholas presented a nice walkthrough of reproducing a famous IPCC figure with xarray-datatree. Here, we attempt to achieve the same with ESMValCore — the workflow engine that powers the more widely known ESMValTool. Both xarray-datatree and ESMValCore facilitate the analysis of large climate datasets, but our approach is quite different. For example, xarray-datatree tries to facilitate any hierarchical file structure (more generic), whereas ESMValCore focuses on facilitating CMIP, or CMIP-like data only (more specific, thus tailored). Seeing them side by side is food for thought.

In case you are not familiar: ESMValTool is a software project that was designed by and for climate scientists to evaluate CMIP data in a standardized and reproducible manner (check out a recent blog here). Several years ago, the project was split in two parts: ESMValCore implements the core functionality, whereas ESMValTool is essentially a big collection of “recipes” to reproduce a wide range of CMIP analytics — including some of the IPCC figures. While ESMValCore has matured as a reliable foundation for the ESMValTool, recent additions also make it attractive as a lightweight alternative to its hefty sibling.
To give you an impression of ESMValCore’s look and feel, we start with a complete code block that exactly reproduces Tom’s figure. In the remainder of this post, we’ll dive into the details: the dataset interface, automatic ESGF downloads, CMOR checks and fixes, and exporting as recipe, meanwhile touching upon some of the similarities and differences with xarray-datatree. At the end of the blogpost we’ll build an ESMValTool recipe that reproduces the same figure with all available models and ensemble members.
import cf_units
import matplotlib.pyplot as plt
from iris import quickplot
from esmvalcore.config import CFG
from esmvalcore.dataset import Dataset
from esmvalcore.preprocessor import annual_statistics, anomalies, area_statistics
# Settings for automatic ESGF search
CFG['search_esgf'] = 'when_missing'
# Declare common dataset facets
template = Dataset(
short_name='tos',
mip='Omon',
project='CMIP6',
exp= '*', # We'll fill this below
dataset='*', # We'll fill this below
ensemble='r4i1p1f1',
grid='gn',
)
# Substitute data sources and experiments
datasets = []
for dataset_id in ["CESM2", "MPI-ESM1-2-LR", "IPSL-CM6A-LR"]:
for experiment_id in ['ssp126', 'ssp585']:
dataset = template.copy(dataset=dataset_id, exp=['historical', experiment_id])
dataset.add_supplementary(short_name='areacello', mip='Ofx', exp='historical')
dataset.augment_facets()
datasets.append(dataset)
# Set the reference period for anomalies
reference_period = {
"start_year": 1950, "start_month": 1, "start_day": 1,
"end_year": 1979, "end_month": 12, "end_day": 31,
}
# (Down)load, pre-process, and plot the cubes
for dataset in datasets:
cube = dataset.load()
cube = area_statistics(cube, operator='mean')
cube = anomalies(cube, reference=reference_period, period='month') # notice 'month'
cube = annual_statistics(cube, operator='mean')
cube.convert_units('degrees_C')
# Make sure all datasets use the same calendar for plotting
tcoord = cube.coord('time')
tcoord.units = cf_units.Unit(tcoord.units.origin, calendar='gregorian')
# Plot
quickplot.plot(cube, label=f"{dataset['dataset']} - {dataset['exp']}")
# Show the plot
plt.legend()
plt.show()
Cool! This looks exactly like the figure in Tom’s post 🎉. With roughly the same amount of code. If you haven’t read Tom’s post, this figure shows the historical and projected rise in sea-surface temperature from different climate models and future emission scenario’s.
Key takeaway 🔑
If there is one thing to note from this little script, it is how “scientifically meaningful” it is. For example, we never got to see actual files. We simply defined our datasets with meaningful facets, as described in the CMIP controlled vocabulary. In the background, ESMValCore located the corresponding files on ESGF, downloaded them to our local environment (if we didn’t have them yet), loaded them into memory, checked adherence to the CMOR conventions, and applied fixes for known issues. But those are technical details, not science.
ESMValCore, in the spirit of ESMValTool, focuses very much on what to do, instead of how.
The inner workings ⚙️
It’s worth dissecting how ESMValCore does things, though. Firstly because you’ll need some understanding to wield it effectively. But mostly because we scientists are often trying to solve the same problems, so it’s interesting to see how ESMValCore tackles some of these issues so you don’t have to.
Configuration
ESMValCore works with a configuration file. This is where you store information about, for example, how your data is organized on disk. The defaults are pretty good, we only had to enable automatic downloads. Let’s have a look at some of the other settings.
print({key: CFG[key]
for key in ['download_dir', 'drs', 'output_dir', 'rootpath']
}){
'download_dir': PosixPath('/home/peter/climate_data'),
'drs': {'CMIP3': 'ESGF', 'CMIP5': 'ESGF', 'CMIP6': 'ESGF', 'CORDEX': 'ESGF', 'obs4MIPs': 'ESGF'},
'output_dir': PosixPath('/home/peter/esmvaltool_output'),
'rootpath': {'default': [PosixPath('/home/peter/climate_data')]}
}The default configuration specifies that data will be downloaded to a folder called climate data in my home directory. The rootpath setting specifies all folders where ESMValCore should look for data, and it is set to the same default. Finally, ESMValCore defines a dedicated folder to store output. Every ESMValTool run or session will get its own subdirectory in there.
The key point here is that you don’t have to worry about data management. You can configure some folders if you want to, but even that is not strictly necessary. If you’re working on dedicated climate data infrastructure such as Jasmin or DKRZ, you can also configure ESMValCore to use the Data Reference Syntax (DRS, the filenames + folder structure) used on these machines.
Data discovery 🔍
Let’s have a closer look at the dataset definition. What happened, for example, when we called augment_facets?
dataset = Dataset(
short_name='tos',
mip='Omon',
project='CMIP6',
exp='historical',
dataset='CESM2',
ensemble='r4i1p1f1',
grid='gn',
)
dataset.augment_facets()
print(dataset)Dataset:
{'dataset': 'CESM2',
'project': 'CMIP6',
'mip': 'Omon',
'short_name': 'tos',
'activity': 'CMIP',
'ensemble': 'r4i1p1f1',
'exp': 'historical',
'frequency': 'mon',
'grid': 'gn',
'institute': ['NCAR'],
'long_name': 'Sea Surface Temperature',
'modeling_realm': ['ocean'],
'original_short_name': 'tos',
'standard_name': 'sea_surface_temperature',
'units': 'degC'}
session: 'session-405b0393-0e28-4dae-836e-0d5961e3d30b_20230609_084132'ESMValCore auto-completed our Dataset based on the information it got from the CMOR tables. With this specification, ESMValCore can automatically search both your local filesystem and the ESGF for available copies of the dataset. Let’s make things a bit more interesting, and look for all available ensemble members. The from_files() method is used to build a list of available dataset based on the search fields.
CFG['search_esgf'] = 'always'
dataset_search = Dataset(
short_name='tos',
mip='Omon',
project='CMIP6',
exp='historical',
dataset='CESM2',
ensemble='*',
grid='gn',
)
ensemble_datasets = list(dataset_search.from_files())
print([ds['ensemble'] for dataset in ensemble_datasets])[
'r10i1p1f1',
'r11i1p1f1',
'r1i1p1f1',
'r2i1p1f1',
'r3i1p1f1',
'r4i1p1f1',
'r5i1p1f1',
'r6i1p1f1',
'r7i1p1f1',
'r8i1p1f1',
'r9i1p1f1'
]Apparently there’s 11 ensemble members available for this model.
The wildcard search functionality ( '*' ) is incredibly useful, as there are often inconsistencies in availability between datasets. Asking for ensemble member 1 through 11 may work for CESM2 today, but not for another model, or it may be different tomorrow.
What if we wanted to plot all available data?
CFG['search_esgf'] = 'always'
dataset_search= Dataset(
short_name='tos',
mip='Omon',
project='CMIP6',
exp=['historical', 'ssp585'],
dataset='*',
ensemble='*',
institute='*',
grid='gn',
)
all_of_cmip = list(dataset_search.from_files())
print(len(all_of_cmip))821That’s a lot of datasets! We’ll save that for the end of the post.
Adding supplementary information
To arrive at global mean temperature, we needed to calculate an area-weighted average. The data for ocean temperature comes at the native model grid, which is irregular and the grid cell area is not easily obtained. To address exactly this issue, the CF conventions include a specification of cell measures. ESMValCore supports this functionality and makes it easy to add cell measures to a dataset. In our case, we need the variable called areacello.
# Discard augmented facets as they will be different for areacello
dataset = Dataset(**dataset.minimal_facets)
# Add areacello as supplementary dataset
dataset.add_supplementary(short_name='areacello', mip='Ofx')
# Autocomplete and inspect
dataset.augment_facets()
print(dataset.summary())Dataset:
{'dataset': 'CESM2',
'project': 'CMIP6',
'mip': 'Omon',
'short_name': 'tos',
'activity': 'CMIP',
'ensemble': 'r4i1p1f1',
'exp': 'historical',
'frequency': 'mon',
'grid': 'gn',
'institute': ['NCAR'],
'long_name': 'Sea Surface Temperature',
'modeling_realm': ['ocean'],
'original_short_name': 'tos',
'standard_name': 'sea_surface_temperature',
'units': 'degC'}
supplementaries:
{'dataset': 'CESM2',
'project': 'CMIP6',
'mip': 'Ofx',
'short_name': 'areacello',
'activity': 'CMIP',
'ensemble': 'r4i1p1f1',
'exp': 'historical',
'frequency': 'fx',
'grid': 'gn',
'institute': ['NCAR'],
'long_name': 'Grid-Cell Area for Ocean Variables',
'modeling_realm': ['ocean'],
'original_short_name': 'areacello',
'standard_name': 'cell_area',
'units': 'm2'}
session: 'session-ccace7d0-dc3b-4e03-87ea-2716aa127618_20230609_085322'These ancillary datasets are not always consistently available for each variant of a dataset. ESMValCore includes some convenience functionality that tries to find a matching variable if the exact match is not available. For example, it may take the grid cell area from another ensemble member. In this case, it looks like we have an exact match.
Data (down)loading
We now arrive at the part of the script that calls dataset.load(). In the background, ESMValCore automatically located the files on ESGF and downloaded them for us. Let’s illustrate this.
# Before load
print(dataset.files)[
ESGFFile:CMIP6/CMIP/NCAR/CESM2/historical/r4i1p1f1/Omon/tos/gn/v20190308/tos_Omon_CESM2_historical_r4i1p1f1_gn_
185001-201412.nc on hosts ['aims3.llnl.gov', 'esgf-data.ucar.edu', 'esgf-data04.diasjp.net', 'esgf.ceda.ac.uk',
'esgf3.dkrz.de']
]# After load (and re-defining the dataset to trigger a new search)
print(dataset.files)[LocalFile('/home/peter/climate_data/CMIP6/CMIP/NCAR/CESM2/historical/r4i1p1f1/Omon/tos/gn/v20190308/tos_Omon_CESM2_historical_r4i1p1f1_gn_185001-201412.nc')]Notice that there were copies of this file available on 5 different ESGF nodes. ESMValCore automatically selects the fastest available server and stored the dataset according to the standard CMOR data reference syntax.
For our example dataset, all the data is apparently contained within one file. However, it’s not always like this. If we look, for example, at another ensemble member, we can see that it is stored in chunks of 50 years:
print(ensemble_datasets[1].files)[ESGFFile:CMIP6/CMIP/NCAR/CESM2/historical/r10i1p1f1/Omon/tos/gn/v20190313/tos_Omon_CESM2_historical_r10i1p1f1_gn_185001-189912.nc on hosts ['aims3.llnl.gov', 'esgf-data.ucar.edu', 'esgf-data04.diasjp.net', 'esgf.ceda.ac.uk', 'esgf3.dkrz.de'],
ESGFFile:CMIP6/CMIP/NCAR/CESM2/historical/r10i1p1f1/Omon/tos/gn/v20190313/tos_Omon_CESM2_historical_r10i1p1f1_gn_190001-194912.nc on hosts ['aims3.llnl.gov', 'esgf-data.ucar.edu', 'esgf-data04.diasjp.net', 'esgf.ceda.ac.uk', 'esgf3.dkrz.de'],
ESGFFile:CMIP6/CMIP/NCAR/CESM2/historical/r10i1p1f1/Omon/tos/gn/v20190313/tos_Omon_CESM2_historical_r10i1p1f1_gn_195001-199912.nc on hosts ['aims3.llnl.gov', 'esgf-data.ucar.edu', 'esgf-data04.diasjp.net', 'esgf.ceda.ac.uk', 'esgf3.dkrz.de'],
ESGFFile:CMIP6/CMIP/NCAR/CESM2/historical/r10i1p1f1/Omon/tos/gn/v20190313/tos_Omon_CESM2_historical_r10i1p1f1_gn_200001-201412.nc on hosts ['aims3.llnl.gov', 'esgf-data.ucar.edu', 'esgf-data04.diasjp.net', 'esgf.ceda.ac.uk', 'esgf3.dkrz.de']]In this case, ESMValCore automatically concatenates the data for us.
You may have noticed that we assigned the result of the load method to a new variable called cube:
cube = dataset.load()Under the hood, ESMValCore uses iris to represent data cubes. Compared to xarray, iris is more strict on checking adherence to CF conventions. This can make it harder to work with, but it also acts as a safeguard against unexpected behaviour.
Where Tom used xMIP, ESMValCore comes with builtin checks and if there are any (known) issues with the datasets, it automatically fixes them. Also, it automatically loads all supplementary datasets. Notice how the cell area is present as a cell measure.
print(cube)sea_surface_temperature / (degC) (time: 1980; cell index along second dimension: 384; cell index along first dimension: 320)
Dimension coordinates:
time x - -
cell index along second dimension - x -
cell index along first dimension - - x
Auxiliary coordinates:
latitude - x x
longitude - x x
Cell measures:
cell_area - x x
Cell methods:
mean where sea area
mean time
Attributes:
Conventions 'CF-1.7 CMIP-6.2'
activity_id 'CMIP'
branch_method 'standard'
branch_time_in_child 0
branch_time_in_parent -492385
case_id '18'
cesm_casename 'b.e21.BHIST.f09_g17.CMIP6-historical.004'
contact 'cesm_cmip6@ucar.edu'
data_specs_version '01.00.29'
description 'This may differ from "surface temperature" in regions of sea ice or floating ...'
experiment 'all-forcing simulation of the recent past'
experiment_id 'historical'
external_variables 'areacello'
forcing_index 1
frequency 'mon'
further_info_url 'https://furtherinfo.es-doc.org/CMIP6.NCAR.CESM2.historical.none.r4i1p1 ...'
grid 'native gx1v7 displaced pole grid (384x320 latxlon)'
grid_label 'gn'
id 'tos'
initialization_index 1
institution 'National Center for Atmospheric Research, Climate and Global Dynamics Laboratory, ...'
institution_id 'NCAR'
license 'CMIP6 model data produced by <The National Center for Atmospheric Research> ...'
mipTable 'Omon'
mip_era 'CMIP6'
model_doi_url 'https://doi.org/10.5065/D67H1H0V'
nominal_resolution '100 km'
out_name 'tos'
parent_activity_id 'CMIP'
parent_experiment_id 'piControl'
parent_mip_era 'CMIP6'
parent_source_id 'CESM2'
parent_time_units 'days since 1850-1-1 00:00:00'
parent_variant_label 'r1i1p1f1'
physics_index 1
product 'model-output'
prov 'Omon ((isd.003))'
realization_index 4
realm 'ocean'
source 'CESM2 (2017): atmosphere: CAM6 (0.9x1.25 finite volume grid; 288 x 192 ...'
source_id 'CESM2'
source_type 'AOGCM BGC'
sub_experiment 'none'
sub_experiment_id 'none'
table_id 'Omon'
time 'time'
time_label 'time-mean'
time_title 'Temporal mean'
title 'Sea Surface Temperature'
type 'real'
variable_id 'tos'
variant_info 'CMIP6 20th century experiments (1850-2014) with CAM6, interactive land ...'
variant_label 'r4i1p1f1'Pre-processing 🛠️
ESMValCore comes with a large suite of built-in preprocessing functions. These functions have been designed as scientifically sound default implementations for frequently performed operations. An important idea underpinning ESMValCore (&Tool)’s philosophy is that standardization facilitates comparison between, and reproducibility of, our data analysis workflows. Moreover, by bundling our efforts we can develop high quality preprocessor functions more effectively. In that spirit it would be good to see how xMIP could be integrated with ESMValCore’s CMOR checks and fixes.
We won’t go into detail on each of the preprocessing functions applied above, as they’re fairly self-explanatory. One thing to highlight though, is that in our calculation of anomalies, we deviated a little bit from Tom’s method. He subtracted the overall average of 1950–1980; we used monthly means over that period. It’s not really necessary here, but it facilitates comparing changes in summer temperature, for example 😎.
cube = area_statistics(cube, operator='mean')
cube = anomalies(cube, reference=reference_period, period='month')
cube = annual_statistics(cube, operator='mean')
cube.convert_units('degrees_C')Custom code
Up to this point, everything we’ve done was “pure” ESMValCore. However, in every data analysis workflow, there comes a point where you want to do custom things. In the traditional context of ESMValTool, such custom code would be added as a “diagnostic script”. In the context of this notebook, we can simply start working with the cube in whatever way we like.
This can be a good moment to thank iris for its services, and continue with xarray if you prefer. For example:
import xarray as xr
da = xr.DataArray.from_iris(cube)
da.plot()
print(da)<xarray.DataArray 'tos' (time: 165)>
dask.array<filled, shape=(165,), dtype=float32, chunksize=(1,), chunktype=numpy.ndarray>
Coordinates:
* time (time) object 1850-07-02 13:00:00.000001 ... 2014-07-02 12:00:00
nlon int64 ...
nlat int64 ...
lat float64 ...
lon float64 ...
year (time) int64 ...
Attributes: (12/57)
standard_name: sea_surface_temperature
long_name: Sea Surface Temperature
units: degrees_C
Conventions: CF-1.7 CMIP-6.2
activity_id: CMIP
case_id: 18
... ...
time: time
time_label: time-mean
time_title: Temporal mean
title: Sea Surface Temperature
type: real
cell_methods: area: mean where sea time: mean longitude: latitu...
Reproducibility: convert to recipe
Traditionally, ESMValTool was designed to work with recipes: static, human-readable files that declare a worfklow from start to finish. This comes back to what we said earlier about describing what to do instead of how. ESMValCore helps us to start building a recipe. With the following code, we can generate the datasets and diagnostics sections of the recipe:
from esmvalcore.dataset import datasets_to_recipe
import yaml
for dataset in ensemble_datasets:
dataset.facets['diagnostic'] = 'easy_ipcc'
print(yaml.safe_dump(datasets_to_recipe(datasets)))datasets:
- dataset: CESM2
ensemble: r4i1p1f1
institute: NCAR
- dataset: IPSL-CM6A-LR
ensemble: r4i1p1f1
institute: IPSL
- dataset: MPI-ESM1-2-LR
ensemble: r4i1p1f1
institute: MPI-M
- dataset: TaiESM1
ensemble: r1i1p1f1
institute: AS-RCEC
- dataset: AWI-CM-1-1-MR
ensemble: r(1:5)i1p1f1
institute: AWI
- dataset: AWI-ESM-1-1-LR
ensemble: r1i1p1f1
institute: AWI
- dataset: BCC-CSM2-MR
ensemble: r(1:3)i1p1f1
institute: BCC
...
diagnostics:
easy_ipcc:
variables:
tos:
exp:
- historical
- ssp585
grid: gn
mip: Omon
project: CMIP6You still have to add the preprocessors and some metadata (a short description etc.). We envision a workflow where you use ESMValCore interactively for most of your exploratory work, and then port it to a recipe for sharing and reproducibility.
To complete this post, we’ve gone ahead and extended the recipe above to include all the available CMIP6 data and make a nice plot. As you might expect, this required more labour due to dataset issues for which no fixes were available, and a bit of extra tinkering to make the figure look more like the IPCC version. You can find the corresponding recipe and diagnostic script here. Be careful with running it, though! This recipe will try to download almost twenty-thousand files… Running this on the German climate compute service, we get the following figure:
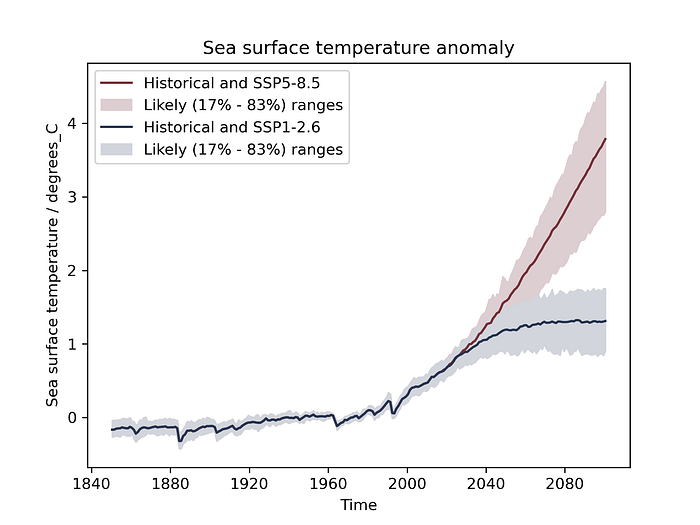
Summary
ESMValCore is great addition to any climate analysis toolbox. Its key strengths are its its approach to streamlining workflows to achieve scientific rigor and reproducibility, and its tight integration with the ESGF and CMOR standards.
If you regularly work with CMIP data, sometimes struggle to retrieve data from ESGF, frequently encounter incompatible datasets, or want to make your workflows available to others, you should definitely give it a shot.

