Cracking the (moisture) tracking code
An exclusive interview with our project partners
This post is part of a series on our 2021 Small Scale Initiative Call in Software Performance Optimization. This week’s highlight: “Optimizing tracking of moisture in the atmosphere”.
What is moisture tracking? Can Python deliver optimal performance? What’s it like to have others modify your code? How can a team avoid alienation in coding? Will the output of this project be part of CMIP? Find out in this exclusive interview with project team members Imme Benedict, Ruud van der Ent, Chris Weijenborg, and Peter Kalverla!

Chris, you’re an expert in atmospheric dynamics. Can you explain what moisture tracking is, and why it is useful?
Chris: The essential question you want to answer with moisture tracking is where moisture leading to precipitation in a certain area is coming from. This can be related to a particular event, think about for example the floods in West-Europe in 2021, but also related to the climatological precipitation. This is useful, since it gives us other insights then just looking at precipitation and or wind fields directly. For example, if the sea surface temperature is increasing in a warmer climate, does this lead to an increased climatological precipitation at another location? Or are the Floods in 2021 caused by increased sea surface temperatures in the Mediterranean Sea or the increased soil moisture over the continent? You might wonder now how all of this works: it’s complicated, but we have a nice animation to show the basics:

Imme, you were the main applicant for this project. What was your original goal with the proposal?
Imme: I had been working in my PhD with the WAM2layers model and also adapted parts of the code. When I got a position as lecturer and researcher, I was keen on continuing the work on moisture tracking, and one way was to work with MSc thesis projects. However, the tool became a bit outdated as it was written to use ERA-Interim dataset as input, while for most recent events only the newest dataset ERA5 was available, as the ERA-Interim dataset was phased out. Therefore,
I became hesitant to use moisture tracking in my own and students research, which I thought was a shame.
Then I wrote this proposal to update and speed-up the code such that researchers new in the field (like students) could easily start to use it.
Ruud, as the original developer of WAM2layers you published your code many years ago. What were your expectations back then? And how do you look back on that today?
Ruud: Initially I just wanted to archive the code, so other researchers would more easily be able to find it. I naively thought of the code as something quite static. Since then, demand for moisture tracking in various fields of application has increased enormously and so has the importance to develop and maintain the code. I hope that with the user community around WAM2layers we can keep the software up to date with the latest developments and relevant for several years to come.
Peter, you have a background in meteorology @ Wageningen University. What was it like to go back to your roots in this project?
Peter: Indeed, this project was right up my alley. I benefited a lot from my meteorology background and I enjoyed delving into some of the equations I’d almost forgotten about. I also liked the collaboration in this project. It felt like a real team effort, where everyone brought their own unique expertise.
When I left Wageningen to join the eScience Center, I wanted to improve my own research software engineering skills so I could apply them to the benefit of academic research. I think that really worked out well with this project.
Now that we’re past the introductions, let’s take a deeper dive into the project. You mentioned the code was too slow to work with high-resolution data like ERA5. Did you solve this problem, and how?
Peter: Yes, we did. The easiest win was changing the code from Python2 to Python3, and then some relatively straightforward changes, for example better use of numpy’s broadcasting capabilities.
The main bottleneck, however, was the memory use. The model was using a nested time loop, where the outer loop was over the input files, and the inner loop over the hourly data interpolated to an even finer time step (see below). All the interpolated time steps were loaded in memory at once. The upgraded code runs a single loop over the fine-grained model time steps, where the data is interpolated on the fly and only the two neighboring (hourly) time steps are loaded in memory.

WAM2layers was originally written in Matlab, then translated to Python. Wasn’t it time for another switch, especially considering Python’s reputation regarding performance?
Peter: We considered it. I’ve been experimenting a bit with Julia in the past and it seems like a suitable alternative. However, we wanted to make sure that the code was still understandable for scientists or students: even if they are not actively changing the code, it’s good if they can understand what’s going on. Python still is by far the most widely known language in the field.
Moreover, Python is fast enough for now. For most operations we use highly optimized numpy functions. If we wanted to squeeze out even more we could still look into numba, for example. Having said that, some of the changes we made to the code structure do actually make it easier to replace expensive operations with optimized code in another language, should we ever wish to do that.
In the end, you did more than make it faster. Can you elaborate on some of the unexpected changes?
Peter: yes, one example is that we made it easier to (pip) install the model and use it from the command line.
Ruud:
People can now get the software working in a matter of minutes. One does not need to be an expert anymore, which is a great development.
However, when people do research with it, I still hope that they involve someone from the core development team as there might be some tricky devils in the details.
In retrospect, what are the main things you got out of this project?
Ruud: Personally, I really enjoyed two things: 1) working in a horizontal team, and 2) blocking time in my agenda to do some coding.
Chris: I really enjoyed learning something new again, moreover in the meanwhile I also was ‘forced’ to learn version control with Git.
Imme: Teamwork, and learning Git! But also the possibility to have students working with the tool again.
Can you elaborate on the student projects?
Ruud & Imme: Sure! Below are the results from 4 student projects: Wenyu looked at monsoon moisture source for the Yangtze River Basin, Rens studied trends in moisture sources related to rising lakes in Keny, Emma studied the drivers of rainfall variability in Surinam, and Vincent used WAM2layers to study the moisture sources over the Amazon region during August 2023 when a big field campaign took place to understand biosphere-atmosphere interactions.
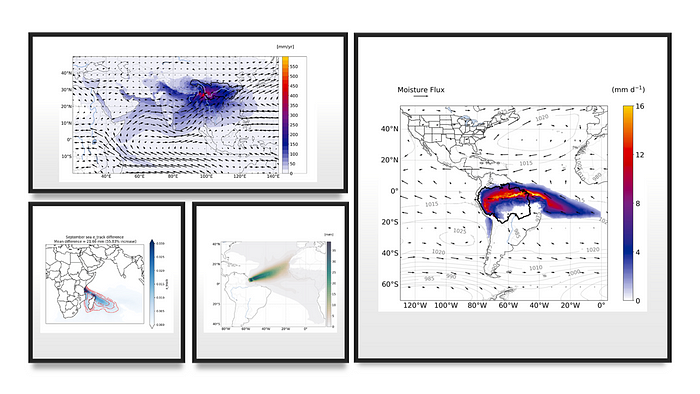
Recently a follow-up project was granted. So this story will continue?
Ruud: Absolutely, with the NWO Open Science project and our own time we want to make WAM2layers even more user-friendly, increase the number of features, applicability to climate models, and get a better grip on the uncertainties. To this end we will also engage with the wider moisture tracking community.
Will CMIP7 include an “Atmospheric moisture tracking-MIP” in the future?
Imme: Ha, that would be amazing of course, but realistically I think there are still some steps in between before such a big goal can be achieved. We are currently initiating a moisture tracking intercomparison project, where multiple moisture tracking models will run the same case to address uncertainty of moisture sources between models. This project will be supported by a workshop at the Lorentz centre in Leiden in May 2024.
This post is part of a series on our 2021 Small Scale Initiative Call in Software Performance Optimization. See also our post on the project Minds for Mobile Agents.

